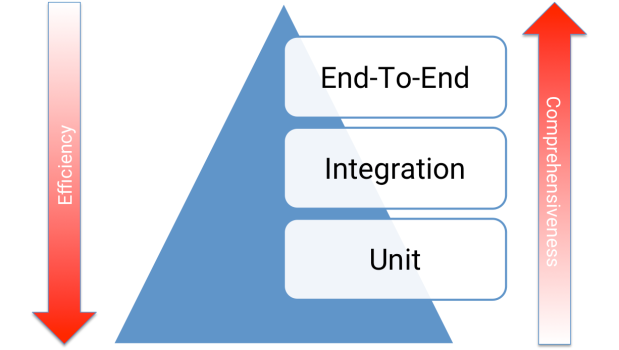
The “Testing Pyramid” is an industry-standard guideline for functional test case development. Love it or hate it, the Pyramid has endured since the mid-2000’s because it continues to be practical. So, what is it, and how can it help us write better tests?
Layers
The Testing Pyramid has three classic layers:
- Unit tests are at the bottom. Unit tests directly interact with product code, meaning they are “white box.” Typically, they exercise functions, methods, and classes. Unit tests should be short, sweet, and focused on one thing/variation. They should not have any external dependencies – mocks/monkey-patching should be used instead.
- Integration tests are in the middle. Integration tests cover the point where two different things meet. They should be “black box” in that they interact with live instances of the product under test, not code. Service call tests (REST, SOAP, etc.) are examples of integration tests.
- End-to-end tests are at the top. End-to-end tests cover a path through a system. They could arguably be defined as a multi-step integration test, and they should also be “black box.” Typically, they interact with the product like a real user. Web UI tests are examples of integration tests because they need the full stack beneath them.
All layers are functional tests because they verify that the product works correctly.
Proportions
The Testing Pyramid is triangular for a reason: there should be more tests at the bottom and fewer tests at the top. Why?
- Distance from code. Ideally, tests should catch bugs as close to the root cause as possible. Unit tests are the first line of defense. Simple issues like formatting errors, calculation blunders, and null pointers are easy to identify with unit tests but much harder to identify with integration and end-to-end tests.
- Execution time. Unit tests are very quick, but end-to-end tests are very slow. Consider the Rule of 1’s for Web apps: a unit test takes ~1 millisecond, a service test takes ~1 second, and a Web UI test takes ~1 minute. If test suites have hundreds to thousands of tests at the upper layers of the Testing Pyramid, then they could take hours to run. An hours-long turnaround time is unacceptable for continuous integration.
- Development cost. Tests near the top of the Testing Pyramid are more challenging to write than ones near the bottom because they cover more stuff. They’re longer. They need more tools and packages (like Selenium WebDriver). They have more dependencies.
- Reliability. Black box tests are susceptible to race conditions and environmental failures, making them inherently more fragile. Recovery mechanisms take extra engineering.
The total cost of ownership increases when climbing the Testing Pyramid. When deciding the level at which to automate a test (and if to automate it at all), taking a risk-based strategy to push tests down the Pyramid is better than writing all tests at the top. Each proportionate layer mitigates risk at its optimal return-on-investment.
Practice
The Testing Pyramid should be a guideline, not a hard rule. Don’t require hard proportions for test counts at each layer. Why not? Arbitrary metrics cause bad practices: a team might skip valuable end-to-end tests or write needless unit tests just to hit numbers. W. Edwards Deming would shudder!
Instead, use loose proportions to foster better retrospectives. Are we covering too many input combos through the Web UI when they could be checked via service tests? Are there unit test coverage gaps? Do we have a pyramid, a diamond, a funnel, a cupcake, or some other wonky shape? Each layer’s test count should be roughly an order of magnitude smaller than the layer beneath it. Large Web apps often have 10K unit tests, 1K service tests, and a few hundred Web UI tests.
Resources
Check out these other great articles on the Testing Pyramid:
- TestPyramid by Martin Fowler
- The Practical Test Pyramid by Ham Vocke
- Test Pyramid: the key to good automated test strategy by Tim Cochran
- Just Say No to More End-to-End Tests by Mike Wacker