AI coding agents following BDD (Behavior-Driven Development) principles can write great Gherkin scenarios if they are given the proper rules. Without explicit rules, AI-generated Gherkin often drifts into vague Then steps, UI-heavy scripts, multi-behavior scenarios, and placeholder examples that read like filler. That is not a model problem alone; it is a missing context problem.
I have written Gherkin Guidelines for AI, an open-source context file created to become a default BDD reference for AI-assisted scenario writing, AI code review, and Gherkin-based test automation. It is one Markdown file you can attach to Cursor, Claude, Copilot, Codex, or any tool that accepts project context.
Place it in your own project alongside your specs or context files.
Wire it up to your project’s rules, skills, or sub-agents so your AI coding agents will abide by it.
Please review the repository’s README for full setup and usage instructions.
When you are ready, try it on your next user story: load the guidelines, ask your agent for scenarios, and see how it feels when everyone is reading from the same playbook. Good specs are a team sport, and this file is here to make your first pass a little lighter and a lot clearer. Whether you want to simply code the vibes or do all-out Spec-Driven Development, I hope that my Gherkin guidelines can help!
Every good software tester knows that a good testing strategy should adhere to the classic Testing Pyramid structure: a strong base of unit tests at the bottom, a solid layer of API tests in the middle, and a few UI tests at the top for good measure. The Testing Pyramid has been around longer than I’ve been working in the software industry, and it is arguably the most prevalent mental model in the discipline of testing.
For years, I abided by the Testing Pyramid. I formed my test plans based upon it. Heck, I even wrote a popular article about it. However, after many years of blindly accepting it, I’m ready to make a rather bold claim: the Testing Pyramid is an antiquated scheme that deceives testers. I’m leaving the pyramid scheme and embracing a new, more modern approach. Even if you think this is heresy, please allow me to explain my rationale.
The Testing Pyramid: A Relic of History
I started my professional career in software in 2007. Back then, Apple had just released the first iPhone, and Facebook was so new that they only allowed college students to create accounts. Web applications, RESTful architecture, and Selenium were all new things. Developing and testing software systems looked much different.
The Testing Pyramid evolved as a simple mental model to help testers decide what to test and how to test it based on the constraints of the time. Web UI testing was notoriously difficult. Browsers were not as standardized as they are today. Selenium WebDriver enabled UI automation but required testers to write their own frameworks around it. Test execution was often slow and flaky. As a result, testers called UI tests “bad” and did everything they could to avoid them, favoring lower-level tests instead. Unit tests were “good” because they were fast, reliable, and close to the code they covered. Plus, code coverage tools could automatically quantify coverage levels and identify gaps. API tests were “okay” because they were typically small and fast, even if they needed to make a network hop to a live environment. Thus, a “proper” test strategy took a pyramidal shape that favored lower level tests for their speed and reliability. It made sense at the time.
Are We Stuck in the Past?
The factors that pushed strategies to take a triangular shape have changed since the inception of the Testing Pyramid all those years ago. Pyramids now feel like relics of ancient history. Let’s take a reality check.
UI testing tools are better, faster, and more reliable. New frameworks like Playwright and Cypress provide greater stability through automatic waiting, faster execution times, and overall better testing experiences. Selenium is still kicking with the BiDi protocol for better testing support, Selenium Manager for automatic driver management, and a plethora of community projects (like Boa Constrictor) helping testers maximize Selenium’s potential.
Traditional API testing can largely be replaced by other kinds of tests. Internal handler unit tests can cover the domain logic for what happens inside the services. Contract tests can cover the handshakes between different services to make sure updates to one won’t break the integrations with others. And UI tests can make sure the system works as a whole.
Test orchestration can now run tests continuously. Tests can run for every code change. They can run for pull requests. Some developers even run end-to-end tests locally before committing changes. The ability to deliver fast feedback on important areas matters far more than the types or times of tests.
Therefore, it is wrong to say a test is bad simply based on its type. All test types are good because they mitigate different kinds of risks. We should focus on building robust continuous feedback loops rather than quotas for test types.
The Testing Skyscraper: A New Model
I think a better mental model for modern testing is the Testing Skyscraper. The skyscraper is a symbol of industrial might and technological advancement. Each skyscraper has a unique architecture that makes it stand out against the skyline. Pyramids get narrower as you approach the top, but skyscrapers have several levels of varying sizes and layouts, where each floor is tailored to the needs of the building’s tenants.
Skyscrapers are a great analogy for testing strategies because one size does not fit all:
Testers can architect their strategies to meet their needs. They can design it as they see fit.
Testers can build out tests at any level they need. Every level of testing is deemed good if it meets the business needs.
Testers can build out as much testing at each level as they like. A floor may have zero-to-many “tenants.”
Testers can choose to skip tests at different levels as a calculated risk. They’ll just be empty floors in the building until needs change.
New testing tools are as strong as steel. Testers can build strategies that scale upwards and onwards, faster and higher than ever before.
The shape of the skyscraper does NOT imply that there should be an equal number of tests at each level. Instead, the metaphor implies that each test strategy is unique and that each level can be built as needed with the freedom of modern architecture. It’s not about quantities or quotas.
I’ve seen anti-pattern models such as ice cream cones and cupcakes. Testing Pyramid might now be an anti-pattern as well.
Modern Architecture for the Present Day
Pyramids were great for their time. The ancients like the Egyptians, the Sumerians, and the Mayans built impressive pyramids that still stand today. However, no civilization has built new pyramids for centuries, unless you count the ones at the Louvre or in Las Vegas. They’re impractical. They’re short. They require an enormous base. Let’s let go of the past and embrace the modern future. Let’s build structures that reflect our times. Let’s build Testing Skyscrapers that reach for the stars – and look snazzy while doing it.
Java continues to be one of the most popular languages for test automation, and Maven continues to be its most popular build tool. Adding tests in the right place to a Java project with Maven can be a bit tricky, however. Let’s briefly learn how to do it. These steps work for both JUnit and TestNG.
Test code location
Maven project follow the Standard Directory Layout. The main code should go under src/main, while all test code should go under src/test:
src/test/java should hold Java test classes
src/test/resources should hold resource files that tests use
Your project directory should look something like this:
Don’t put test code in the main source folder. You don’t want to include it with the final build artifact. The project might have other files as well, like a README.
Unit tests
The Maven Surefire Plugin runs unit tests during Maven’s test phase. To run unit tests:
Add maven-surefire-plugin to the plugins section of your pom.xml
Name your unit tests *Tests.java
Put them under src/test/java
Mirror the package structure from the main code always
Run tests with mvn test
There are a bunch of options for configuring the Maven Surefire Plugin. If you don’t want to configure anything special, you actually don’t need to add the plugin to the POM file. Nevertheless, it’s good practice to add it to the POM file anyway. Here’s what that would look like:
The Maven Failsafe Plugin runs integration tests during Maven’s integration-test phase. Integration tests are distinct from unit tests due to their external dependencies and should be treated differently. To run integration tests:
Add maven-failsafe-plugin to the plugins section of your pom.xml
Name your unit tests *IT.java
Put them under src/test/java
Mirror the package structure from the main code as appropriate
Run tests with mvn verify
Maven actually has multiple integration test phases: pre-integration-test, integration-test, and post-integration-test to handle appropriate setup, testing, and cleanup. However, none of these phases will cause the build to fail. Instead, use the verify goal to make the build fail when ITs fail.
Like the Maven Surefire Plugin, the Maven Failsafe Plugin has a bunch of options. However, to run integration tests, you must configure the Failsafe plugin in the POM file. Here’s what it looks like:
Running mvn verify includes the compile and test phases
It is also a good practice to run mvn clean before other phases to delete the build output (target/) directory. That way, old class files and test reports are removed before generating new ones. You may also include clean with commands to run tests, like this: mvn clean test or mvn clean verify.
Customizations
You can customize how tests run. For example, you can create a separate directory for integration tests (like src/it instead of src/test). However, I recommend avoiding customizations like this. They require complicated settings in the POM file that are difficult to get right and confusing to maintain. Others who join the project later will expect Maven standards.
Playwright is an awesome new web testing framework, and it can help you take a modern approach to web development. In this article, let’s learn how.
Asking tough questions about testing
Let me ask you a series of questions:
Question 1: Do you like it when bugs happen in your code? Most likely not. Bugs are problems. They shouldn’t happen in the first place, and they require effort to fix. They’re a big hassle.
Question 2: Would you rather let those bugs ship to production? Absolutely not! We want to fix bugs before users ever see them. Serious bugs could cause a lot of damage to systems, businesses, and even reputations. Whenever bugs do slip into production, we want to find them and fix them ASAP.
Question 3: Do you like to create tests to catch bugs before that happens? Hmmm… this question is tougher to answer. Most folks understand that good tests can provide valuable feedback on software quality, but not everyone likes to put in the work for testing.
Why the distaste for testing?
Why doesn’t everyone like to do testing? Testing is HARD! Here are common complaints I hear:
Tests are slow – they take too long to run!
Tests are brittle – they break whenever the app changes!
Tests are flaky – they crash all the time!
Tests don’t make sense – they are complicated and unreadable!
Tests don’t make money – we could be building new features instead!
Tests require changing context – they interrupt my development workflow!
These are all valid reasons. To mitigate these pain points, software teams have historically created testing strategies around the Testing Pyramid, which separates tests by layer from top to bottom:
UI tests
API tests
Component tests
Unit tests
Tests at the bottom were considered “better” because they were closer to the code, easier to automate, and faster to execute. They were also considered to be less susceptible to flakiness and, therefore, easier to maintain. Tests at the top were considered just the opposite: big, slow, and expensive. The pyramid shape implied that teams should spent more time on tests at the base of the pyramid and less time on tests at the top.
End-to-end tests can be very valuable. Unfortunately, the Testing Pyramid labeled them as “difficult” and “bad” primarily due to poor practices and tool shortcomings. It also led teams to form testing strategies that emphasized categories of tests over the feedback they delivered.
Rethinking modern web testing goals
Testing doesn’t need to be hard, and it doesn’t need to suffer from the problems of the past. We should take a fresh, new approach in testing modern web apps.
Here are three major goals for modern web testing:
Focus on building fast feedback loops rather than certain types of tests.
Make test development as fast and painless as possible.
Choose test tooling that naturally complements dev workflows.
These goals put emphasis on results and efficiency. Testing should just be a natural part of development without any friction.
Introducing Playwright
Playwright is a modern web testing framework that can help us meet these goals.
It is an open source project from Microsoft.
It manipulates the browser via (superfast) debug protocols
It works with Chromium/Chrome/Edge, Firefox, and WebKit
It provides automatic waiting, test generation, UI mode, and more
It can test UIs and APIs together
It provides bindings for JavaScript/TypeScript, Python, Java, and C#
Playwright takes a unique approach to browser automation. First of all, it uses browser projects rather than full browser apps. For example, this means you would test Chromium instead of Google Chrome. Browser projects are smaller and don’t use as many resources as full browsers. Playwright also manages the browser projects for you, so you don’t need to install extra stuff.
Second, it uses browsers very efficiently:
Instead of launching a full, new browser instance for each test, Playwright launches one browser instance for the entire suite of tests.
It then creates a unique browser context from that instance for each test. A browser context is essentially like an incognito session: it has its own session storage and tabs that are not shared with any other context. Browser contexts are very fast to create and destroy.
Then, each browser context can have one or more pages. All Playwright interactions happen through a page, like clicks and scrapes. Most tests only ever need one page.
Playwright handles all this setup automatically for you.
Comparing Playwright to other tools
Playwright is not the only browser automation tool out there. The other two most popular tools are Selenium and Cypress. Here is a chart with high-level comparisons:
All three are good tools, and each one has their advantages. Playwright’s main advantages are that offers excellent developer experience with the fastest execution time, multiple language bindings, and several quality-of-life features.
Learning Playwright
If you want to learn how to automate your web tests with Playwright, take my tutorial, Awesome Web Testing with Playwright. All instructions and example code for the tutorial are located in GitHub. This tutorial is designed to be self-guided, so give it a try!
Test Automation University also has a Playwright learning path with introductory and advanced courses:
Playwright is an awesome new framework for modern web testing. Give it a try, and let me know what you automate!
This article is based on my talk at PyCon US 2023. The web app under test and most of the example code is written in Python, but the information presented is applicable to any stack.
There are several great tools and frameworks for automating browser-based web UI testing these days. Personally, I gravitate towards open source projects that require coding skills to use, rather than low-code/no-code automation tools. The big three browser automation tools right now are Selenium, Cypress, and Playwright. There are other great tools, too, but these three seem to be the ones everyone is talking about the most.
It can be tough to pick right right tool for your needs. In this article, let’s compare and contrast these tools.
If you want to run it locally, all you need is Python!
The app is pretty simple. When you first load it, it presents a standard login page. I actually used ChatGPT to help me write the HTML and CSS:
After logging in, you’ll see the reminders page:
The title card at the top has the app’s name, the logo, and a logout button. On the left, there is a card for reminder lists. Here, I have different lists for Chores and Projects. On the right, there is a card for all the reminders in the selected list. So, when I click the Chores list, I see reminders like “Buy groceries” and “Walk the dog.” I can click individual reminder rows to strike them out, indicating that they are complete. I can also add, edit, or delete reminders and lists through the buttons along the right sides of the cards.
Now that we have a web app to test, let’s learn how to use the big three web testing tools to automate tests for it.
Selenium
Selenium WebDriver is the classic and still the most popular browser automation tool. It’s the original. It carries that old-school style and swagger. Selenium manipulates the browser using the WebDriver protocol, a W3C Recommendation that all major browsers have adopted. The Selenium project is fully open source. It relies on open standards, and it is run by community volunteers according to open governance policies. Selenium WebDriver offers language bindings for Java, JavaScript, C#, and – my favorite language – Python.
Selenium WebDriver works with real, live browsers through a proxy server running on the same machine as the target browser. When test automation starts, it will launch the WebDriver executable for the proxy and then send commands through it via the WebDriver protocol.
To set up Selenium WebDriver, you need to install the WebDriver executables on your machine’s system path for the browsers you intend to test. Make sure the versions all match!
Then, you’ll need to add the appropriate Selenium package(s) to your test automation project. The names for the packages and the methods for installation are different for each language. For example, in Python, you’ll probably run pip install selenium.
In your project, you’ll need to construct a WebDriver instance. The best place to do that is in a setup method within a test framework. If you are using Python with pytest, that would go into a fixture like this:
We could hardcode the browser type we want to use as shown here in the example, or we could dynamically pick the browser type based on some sort of test inputs. We may also set options on the WebDriver instance, such as running it headless or setting an implicit wait. For cleanup after the yield command, we need to explicitly quit the browser.
Here’s what a login test would look like when using Selenium in Python:
The test function would receive the WebDriver instance through the browser fixture we just wrote. When I write tests, I follow the Arrange-Act-Assert pattern, and I like to write my test steps using Given-When-Then language in comments.
The first step is, “Given the login page is displayed.” Here, we call “browser dot get” with the full URL for the Bulldoggy app running on the local machine.
The second step is, “When the user logs into the app with valid credentials.” This actually requires three interactions: typing the username, typing the password, and clicking the login button. For each of these, the test must first call “browser dot find element” with a locator to get the element object. They locate the username and password fields using CSS selectors based on input name, and they locate the login button using an XPath that searches for the text of the button. Once the elements are found, the test can call interactions on them like “send keys” and “click”.
Now, one thing to note is that these calls should probably use page objects or the Screenplay Pattern to make them reusable, but I chose to put raw Selenium code here to keep it basic.
The third step is, “Then the reminders page is displayed.” These lines perform assertions, but they need to wait for the reminders page to load before they can check any elements. The WebDriverWait object enables explicit waiting. With Selenium WebDriver, we need to handle waiting by ourselves, or else tests will crash when they can’t find target elements. Improper waiting is the main cause for flakiness in tests. Furthermore, implicit and explicit waits don’t mix. We must choose one or the other. Personally, I’ve found that any test project beyond a small demo needs explicit waits to be maintainable and runnable.
Selenium is great because it works well, but it does have some paint points:
Like we just said, there is no automatic waiting. Folks often write flaky tests unintentionally because they don’t handle waiting properly. Therefore, it is strongly recommended to use a layer on top of raw Selenium like Pylenium, SeleniumBase, or a Screenplay implementation. Selenium isn’t a full test framework by itself – it is a browser automation tool that becomes part of a test framework.
Selenium setup can be annoying. We need to install matching WebDriver executables onto the system path for every browser we test, and we need to keep their versions in sync. It’s very common to discover that tests start failing one day because a browser automatically updated its version and no longer matched its WebDriver executable. Thankfully, a new part of the Selenium project named Selenium Manager now automatically handles the executables.
Selenium-based tests have a bad reputation for slowness. Usually, poor performance comes more from the apps under test than the tool itself, but Selenium setup and cleanup do cause a performance hit.
Cypress
Cypress is a modern frontend test framework with rich developer experience. Instead of using the WebDriver protocol, it manipulates the browser via in-browser JavaScript calls. The tests and the app operate in the same browser process. Cypress is an open source project, and the company behind it sells advanced features for it as a paid service. It can run tests on Chrome, Firefox, Edge, Electron, and WebKit (but not Safari). It also has built-in API testing support. Unfortunately, due to its design, Cypress tests must be written exclusively in JavaScript (or TypeScript).
Here’s the code for the Bulldoggy login test in Cypress in JavaScript:
The steps are pretty much the same as before. Instead of creating some sort of browser object, all Cypress calls go to its cy object. The syntax is very concise and readable. We could even fit in a few more assertions. Cypress also handles waiting automatically, which makes the code less prone to flakiness.
The rich developer experience comes alive when running Cypress tests. Cypress will open a browser window that will visually execute the test in front of us. Every step is traced so we can quickly pinpoint failures. Cypress is essentially a web app that tests web apps.
While Cypress is awesome, it is JavaScript-only, which stinks for folks who use other programming languages. For example, I’m a Pythonista at heart. Would I really want to test a full-stack Python web app like Bulldoggy with a browser automation tool that doesn’t have a Python language binding? Cypress is also trapped in the browser. It has some inherent limitations, like the fact that it can’t handle more than one open tab.
Playwright
Playwright is similar to Cypress in that it’s a modern, open source test framework that is developed and maintained by a company. Playwright manipulates the browser via debug protocols, which make it the fastest of the three tools we’ve discussed today. Playwright also takes a unique approach to browsers. Instead of testing full browsers like Chrome, Firefox, and Safari, it tests the corresponding browser engines: Chromium, Firefox (Gecko), and WebKit. Like Cypress, Playwright can also test APIs, and like Selenium, Playwright offers bindings for multiple popular languages, including Python.
To set up Playwright, of course we need to install the dependency packages. Then, we need to install the browser engines. Thankfully, Playwright manages its browsers for us. All we need to do is run the appropriate “Playwright install” for the chosen language.
Playwright takes a unique approach to browser setup. Instead of launching a new browser instance for each test, it uses one browser instance for all tests in the suite. Each test then creates a unique browser context within the browser instance, which is like an incognito session within the browser. It is very fast to create and destroy – much faster than a full browser instance. One browser instance may simultaneously have multiple contexts. Each context keeps its own cookies and session storage, so contexts are independent of each other. Each context may also have multiple pages or tabs open at any given time. Contexts also enable scalable parallel execution. We could easily run tests in parallel with the same browser instance because each context is isolated.
Let’s see that Bulldoggy login test one more time, but this time with Playwright code in Python. Again, the code is pretty similar to what we saw before. The major differences between these browser automation tools is not so much the appearance of the code but rather how they work and perform:
With Playwright, all interactions happen with the “page” object. By default, Playwright will create:
One browser instance to be shared by all tests in a suite
One context for each test case
One page within the context for each test case
When we read this code, we see locators for finding elements and methods for acting upon found elements. Notice how, like Cypress, Playwright automatically handles waiting. Playwright also packs an extensive assertion library with conditions that will wait for a reasonable timeout for their intended conditions to become true.
Again, like we said for the Selenium example code, if this were a real-world project, we would probably want to use page objects or the Screenplay Pattern to handle interactions rather than raw calls.
Playwright has a lot more cool stuff, such as the code generator and the trace viewer. However, Playwright isn’t perfect, and it also has some pain points:
Playwright tests browser engines, not full browsers. For example, Chrome is not the same as Chromium. There might be small test gaps between the two. Your team might also need to test full browsers to satisfy compliance rules.
Playwright is still new. It is years younger than Selenium and Cypress, so its community is smaller. You probably won’t find as many StackOverflow articles to help you as you would for the other tools. Features are also evolving rapidly, so brace yourself for changes.
Which one should you choose?
So, now that we have learned all about Selenium, Cypress, and Playwright, here’s the million-dollar question: Which one should we use? Well, the best web test tool to choose really depends on your needs. They are all great tools with pros and cons. I wanted to compare these tools head-to-head, so I created this table for quick reference:
In summary:
Selenium WebDriver is the classic tool that historically has appealed to testers. It supports all major browsers and several programming languages. It abides by open source, standards, and governance. However, it is a low-level browser automation tool, not a full test framework. Use it with a layer on top like Serenity, Boa Constrictor, or Pylenium.
Cypress is the darling test framework for frontend web developers. It is essentially a web app that tests web apps, and it executes tests in the same browser process as the app under test. It supports many browsers but must be coded exclusively in JavaScript. Nevertheless, its developer experience is top-notch.
Playwright is gaining popularity very quickly for its speed and innovative optimizations. It packs all the modern features of Cypress with the multilingual support of Selenium. Although it is newer than Cypress and Selenium, it’s growing fast in terms of features and user base.
If you want to know which one I would choose, come talk with me about it! You can also watch my PyCon US 2023 talk recording to see which one I would specifically choose for my personal Python projects.
I started Boa Constrictor back in 2018 because I loathed page objects. On a previous project, I saw page objects balloon to several thousand lines long with duplicative methods. Developing new tests became a nightmare, and about 10% of tests failed daily because they didn’t handle waiting properly.
So, while preparing a test strategy at a new company, I invested time in learning the Screenplay Pattern. To be honest, the pattern seemed a bit confusing at first, but I was willing to try anything other than page objects again. Eventually, it clicked for me: Actors use Abilities to perform Interactions. Boom! It was a clean separation of concerns.
Unfortunately, the only major implementations I could find for the Screenplay Pattern at the time were Serenity BDD in Java and JavaScript. My company was a .NET shop. I looked for C# implementations, but I didn’t find anything that I trusted. So, I took matters into my own hands and implemented the Screenplay Pattern myself in .NET. Initially, I implemented Selenium WebDriver interactions. Later, my team and I added RestSharp interactions. We eventually released Boa Constrictor as an open source project in October 2020 as part of Hacktoberfest.
With Boa Constrictor, I personally sought to reinvigorate interest in the Screenplay Pattern. By bringing the Screenplay Pattern to .NET, we enabled folks outside of the Java and JavaScript communities to give it a try. With our rich docs, examples, and videos, we made it easy to onboard new users. And through conference talks and webinars, we popularized the concepts behind Screenplay, even for non-C# programmers. It’s been awesome to see so many other folks in the testing community start talking about the Screenplay Pattern in the past few years.
I also wanted to provide a standalone implementation of the Screenplay Pattern. Since the Screenplay Pattern is a design for automating interactions, it could and should integrate with any .NET test framework: SpecFlow, MsTest, NUnit, xUnit.net, and any others. With Boa Constrictor, we focused singularly on making interactions as excellent as possible, and we let other projects handle separate concerns. I did not want Boa Constrictor to be locked into any particular tool or system. In this sense, Boa Constrictor diverged from Serenity BDD – it was not meant to be a .NET version of Serenity, despite taking much inspiration from Serenity.
Furthermore, in the design and all the messaging for Boa Constrictor, I strived to make the Screenplay Pattern easy to understand. So many folks I knew gave up on Screenplay in the past because they thought it was too complicated. I wanted to break things down so that any automation developer could pick it up quickly. Hence, I formed the soundbite, “Actors use Abilities to perform Interactions,” to describe the pattern in one line. I also coined the project’s slogan, “Better Interactions for Better Automation,” to clearly communicate why Screenplay should be used over alternatives like raw calls or page objects.
So far, Boa Constrictor has succeeded modestly well in these goals. Now, the project is pursuing one more goal: democratizing the Screenplay Pattern.
At its heart, the Screenplay Pattern is a generic pattern for any kind of interactions. The core pattern should not favor any particular tool or package. Anyone should be able to implement interaction libraries using the tools (or “Abilities”) they want, and each of those libraries should be treated equally without preference. Recently, in our plans for Boa Constrictor 3, we announced that we want to create separate packages for the “core” pattern and for each library of interactions. We also announced plans to add new libraries for Playwright and Applitools. The existing libraries – Selenium WebDriver and RestSharp – need not be the only libraries. Boa Constrictor was never meant to be merely a WebDriver wrapper or a superior page object. It was meant to provide better interactions for any kind of test automation.
In version 3.0.0, we successfully separated the Boa.Constrictor project into three new .NET projects and released a NuGet package for each:
This separation enables folks to pick the parts they need. If they only need Selenium WebDriver interactions, then they can use just the Boa.Constrictor.Selenium package. If they want to implement their own interactions and don’t need Selenium or RestSharp, then they can use the Boa.Constrictor.Screenplay package without being forced to take on those extra dependencies.
Furthermore, we continued to maintain the “classic” Boa.Constrictor package. Now, this package simply claims dependencies on the other three packages in order to preserve backwards compatibility for folks who used previous version of Boa Constrictor. As part of the upgrade from 2.0.x to 3.0.x, we did change some namespaces (which are documented in the project changelog), but the rest of the code remained the same. We wanted the upgrade to be as straightforward as possible.
The core contributors and I will continue to implement our plans for Boa Constrictor 3 over the coming weeks. There’s a lot to do, and we will do our best to implement new code with thoughtfulness and quality. We will also strive to keep everything documented. Please be patient with us as development progresses. We also welcome your contributions, ideas, and feedback. Let’s make Boa Constrictor excellent together.
Boa Constrictor is the .NET Screenplay Pattern. It helps you make better interactions for better test automation!
I originally created Boa Constrictor starting in 2018 as the cornerstone of PrecisionLender‘s end-to-end test automation project. In October 2020, my team and I released it as an open source project hosted on GitHub. Since then, the Boa Constrictor NuGet package has been downloaded over 44K times, and my team and I have shared the project through multiple conference talks and webinars. It’s awesome to see the project really take off!
Unfortunately, Boa Constrictor has had very little development over the past year. The latest release was version 2.0.0 in November 2021. What happened? Well, first, I left Q2 (the company that acquired PrecisionLender) to join Applitools, so I personally was not working on Boa Constrictor as part of my day job. Second, Boa Constrictor didn’t need much development. The core Screenplay Pattern was well-established, and the interactions for Selenium WebDriver and RestSharp were battle-hardened. Even though we made no new releases for a year, the project remained alive and well. The team at Q2 still uses Boa Constrictor as part of thousands of test iterations per day!
The time has now come for new development. Today, I’m excited to announce our plans for the next phase of Boa Constrictor! In this article, I’ll share the vision that the core contributors and I have for the project – tentatively casting it as “version 3.” We will also share a rough timeline for development.
Separate interaction packages
Currently, the Boa.Constrictor NuGet package has three main parts:
The Screenplay Pattern’s core interfaces and classes
This structure is convenient for a test automation project that uses Selenium and RestSharp, but it forces projects that don’t use them to take on their dependencies. What if a project uses Playwright instead of Selenium, or RestAssured.NET instead of RestSharp? What if a project wants to make different kinds of interactions, like mobile interactions with Appium?
At its heart, the Screenplay Pattern is a generic pattern for any kind of interactions. In theory, the core pattern should not favor any particular tool or package. Anyone should be able to implement interaction libraries using the core pattern.
With that in mind, we intend to split the current Boa.Constrictor package into three separate packages, one for each of the existing parts. That way, a project can declare dependencies only on the parts of Boa Constrictor that it needs. It also enables us (and others) to develop new packages for different kinds of interactions.
Playwright support
One of the new interaction packages we intend to create is a library for Playwright interactions.Playwright is a fantastic new web testing framework from Microsoft. It provides several advantages over Selenium WebDriver, such as faster execution, automatic waiting, and trace logging.
We want to give people the ability to choose between Selenium WebDriver or Playwright for their web UI interactions. Since a test automation project would use only one, and since there could be overlap in the names and types of interactions, separating interaction packages as detailed in the previous section will be a prerequisite for developing Playwright support.
We may also try to develop an adapter for Playwright interactions that uses the same interfaces as Selenium interactions so that folks could switch from Selenium to Playwright without rewriting their interactions.
Applitools support
Another new interaction package we intend to create is a library for Applitools interactions.Applitools is the premier visual testing platform. Visual testing catches UI bugs that are difficult to catch with traditional assertions, such as missing elements, broken styling, and overlapping text. A Boa Constrictor package for Applitools interactions would make it easier to capture visual snapshots together with Selenium WebDriver interactions. It would also be an “optional” feature since it would be its own package.
Shadow DOM support
Shadow DOM is a technique for encapsulating parts of a web page. It enables a hidden DOM tree to be attached to an element in the “regular” DOM tree so that different parts between the two DOMs do not clash. Shadow DOM usage has become quite prevalent in web apps these days.
We intend to add support for Selenium interactions to pierce the shadow DOM. Selenium WebDriver requires extra calls to pierce the shadow DOM. Unfortunately, Boa Constrictor’s Selenium interactions currently do not support shadow DOM interactivity. Most likely, we will add new builder methods for Selenium-based Tasks and Questions that take in a locator for the shadow root element and then update the action methods to handle the shadow DOM if necessary.
.NET 7 targets
The main Boa Constrictor project, the unit tests project, and the example project all target .NET 5. Unfortunately, NET 5 is no longer supported by Microsoft. The latest release is .NET 7.
We intend to add .NET 7 targets. We will make the library packages target .NET 7, .NET 5 (for backwards compatibility), and .NET Standard 2.0 (again, for backwards compatibility). We will change the unit test and example projects to target .NET 7 exclusively. In fact, we have already made this change in version 2.0.2!
Dependency updates
Many of Boa Constrictor’s dependencies have released new versions over the past year. GitHub’s Dependabot has also flagged some security vulnerabilities. It’s time to update dependency versions. This is standard periodic maintenance for any project. Already, we have updated our Selenium WebDriver dependencies to version 4.6.
Documentation enhancements
Boa Constrictor has a doc site hosted using GitHub Pages. As we make the changes described above, we must also update the documentation for the project. Most notably, we will need to update our tutorial and example project, since the packages will be different, and we will have support for more kinds of interactions.
What’s the timeline?
The core contributors and I plan to implement these enhancements within the next three months:
Today, we just released two new versions with incremental changes: 2.0.1 and 2.0.2.
This week, we hope to split the existing package into three, which we intend to release as version 3.0.
In December, we will refresh the GitHub Issues for the project.
In January, the core contributors and I will host an in-person hackathon (a “Constrictathon”) in Cary, NC.
In the featured image for this article, you see a beautiful front end. It’s probably not the kind of “front end” you expected. It’s the front end of a 1974 Volkswagen Karmann Ghia. The Karmann Ghia was known as the “poor man’s Porsche.” It’s a very special car. It was actually a collaboration project between Wilhelm Karmann, a German automobile manufacturer, and Carrozzeria Ghia, an Italian automobile designer. Ghia designed the body as a work of art, and Karmann put it on the tried-and-true platform of the classic Volkswagen Beetle. When the Volkswagen executives saw it, they couldn’t say no to mass production.
The Karmann Ghia is a perfect symbol of the state of web development today. We strive to make beautiful front ends with reliable platforms supporting them on the back end. Collaboration from both sides is key to success, but what people remember most is the experience they have with your apps. My mom drove a Karmann Ghia like this when she was a teenager, and to this day she still talks about the good times she had with it.
Good quality, design, and experience are indispensable aspects of front ends – whether for classic cars or for the Web. In this article, I’ll share seven major trends I see in front end web testing. While there’s a lot of cool new things happening, I want y’all to keep in mind one main thing: tools and technologies may change, but the fundamentals of testing remain the same. Testing is interaction plus verification. Tests reveal the truth about our code and our features. We do testing as part of development to gather fast feedback for fixes and improvements. All the trends I will share today are rooted in these principles. With good testing, you can make sure your apps will look visually perfect, just like… you know.
#1. End-to-end testing
Here’s our first trend: End-to-end testing has become a three-way battle. For clarity, when I say “end-to-end” testing, I mean black-box test automation that interacts with a live web app in an active browser.
Historically, Selenium has been the most popular tool for browser automation. The project has been around for over a decade, and the WebDriver protocol is a W3C standard. It is open source, open standards, and open governance. Selenium WebDriver has bindings for C#, Java, JavaScript, Ruby, PHP, and Python. The project also includes Selenium IDE, a record-and-playback tool, and Selenium Grid, a scalable cluster for cross-browser testing. Selenium is alive and well, having just released version 4.
Over the years, though, Selenium has received a lot of criticism. Selenium WebDriver is a low-level protocol. It does not handle waiting automatically, leading many folks to unknowingly write flaky scripts. It requires clunky setup since WebDriver executables must be separately installed. Many developers dislike Selenium because coding with it requires a separate workflow or state of mind from the main apps they are developing.
Cypress was the answer to Selenium’s shortcomings. It aimed to be a modern framework with excellent developer experience, and in a few short years, it quickly became the darling test tool for front end developers. Cypress tests run in the browser side-by-side with the app under test. The syntax is super concise. There’s automatic waiting, meaning less flakiness. There’s visual tracing. There’s API calls. It’s nice. And it took a big chomp out of Selenium’s market share.
Cypress isn’t perfect, though. Its browser support is limited to Chromium-based browsers and Firefox. Cypress is also JavaScript-only, which excludes several communities. While Cypress is open source, it does not follow open standards or open governance like Selenium. And, sadly, Cypress’ performance is slow – equivalent tests run slower than Selenium.
Enter Playwright, the new open source test framework from Microsoft. Playwright is the spiritual successor to Puppeteer. It boasts the wide browser and language compatibility of Selenium with the refined developer experience of Cypress. It even has a code generator to help write tests. Plus, Playwright is fast – multiple times faster than Selenium or Cypress.
Playwright is still a newcomer, and it doesn’t yet have the footprint of the other tools. Some folks might be cautious that it uses browser projects instead of stock browsers. Nevertheless, it’s growing fast, and it could be a major contender for the #1 title. In Applitools’ recent Let The Code Speak code battles, Playwright handily beat out both Selenium and Cypress.
A side-by-side comparison of Selenium, Cypress, and Playwright
Selenium, Cypress, and Playwright are definitely now the “big three” browser automation tools for testing. A respectable fourth mention would be WebdriverIO. WebdriverIO is a JavaScript-based tool that can use WebDriver or debug protocols. It has a very large user base, but it is JavaScript-only, and it is not as big as Cypress. There are other tools, too. Puppeteer is still very popular but used more for web crawling than testing. Protractor, once developed by the Angular team, is now deprecated.
All these are good tools to choose (except Protractor). They can handle any kind of web app that you’re building. If you want to learn more about them, Test Automation University has courses for each.
#2. Component testing
End-to-end testing isn’t the only type of testing a team can or should do. Component testing is on the rise because components are on the rise! Many teams now build shareable component libraries to enforce consistency in their web design and to avoid code duplication. Each component is like a “unit of user interface.” Not only do they make development easier, they also make testing easier.
Component testing is distinct from unit testing. A unit test interacts directly with code. It calls a function or method and verifies its outcomes. Since components are inherently visual, they need to be rendered in the browser for proper testing. They might have multiple behaviors, or they may even trigger API calls. However, they can be tested in isolation of other components, so individually, they don’t need full end-to-end tests. That’s why, from a front end perspective, component testing is the new integration testing.
Storybook is a very popular tool for building and testing components in isolation. In Storybook, each component has a set of stories that denote how that component looks and behaves. While developing components, you can render them in the Storybook viewer. You can then manually test the component by interacting with them or changing their settings. Applitools also provides an SDK for automatically running visual tests against a Storybook library.
The Storybook viewer
Cypress is also entering the component testing game. On June 1, 2022, Cypress released version 10, which included component testing support. This is a huge step forward. Before, folks would need to cobble together their own component test framework, usually as an extension of a unit test project or an end-to-end test project. Many solutions just ran automated component tests purely as Node.js processes without any browser component. Now, Cypress makes it natural to exercise component behaviors individually yet visually.
I love this quote from Cypress about their approach to component testing:
When testing anything for the web, we believe that tests should view and interact with the application in the same way that an actual user does. Anything less, and it’s hard to have confidence that your application is doing what it is supposed to.
This quote hits on something big. So many automated tests fail to interact with apps like real users. They hinge on things like IDs, CSS selectors, and XPaths. They make minimal checks like appearance of certain elements or text. Pages could be completely broken, but automated tests could still pass.
#3. Visual testing
We really want the best of both worlds: the simplicity and sensibility of manual testing with the speed and scalability of automated testing. Historically, this has been a painful tradeoff. Most teams struggle to decide what to automate, what to check manually, and what to skip. I think there is tremendous opportunity in bridging the gap. Modern tools should help us automate human-like sensibilities into our tests, not merely fire events on a page.
That’s why visual testing has become indispensable for front end testing. Web apps are visual encounters. Visuals are the DNA of user experience. Functionality alone is insufficient. Users expect to be wowed. As app creators, we need to make sure those vital visuals are tested. Heaven forbid a button goes missing or our CSS goes sideways. And since we live in a world of continuous development and delivery, we need those visual checkpoints happening continuously at scale. Real human eyes are just too slow.
For example, I could have a login page that has an original version (left) and a changed version (right):
Visual comparison between versions of a login page
Visual testing tools alert you to meaningful changes and make it easy to compare them side-by-side. They catch things you might miss. Plus, they run just like any other automated test suite. Visual testing was tough in the past because tools merely did pixel-to-pixel comparisons, which generated lots of noise for small changes and environmental differences. Now, with a tool like Applitools Visual AI, visual comparisons accurately pinpoint the changes that matter.
Test automation needs to check visuals these days. Traditional scripts interact with only the basic bones of the page. You could break the layout and remove all styling like this, and there’s a good chance a traditional automated test would still pass:
The same login page from before, but without any CSS styling
With visual testing techniques, you can also rethink how you approach cross-browser and cross-device testing. Instead of rerunning full tests against every browser configuration you need, you can run them once and then simply re-render the visual snapshots they capture against different browsers to verify the visuals. You can do this even for browsers that the test framework doesn’t natively support! For example, using a platform like Applitools Ultrafast Test Cloud, you could run Cypress tests against Electron in CI and then perform visual checks in the Cloud against Safari and Internet Explorer, among other browsers. This style of cross-platform testing is faster, more reliable, and less expensive than traditional ways.
#4. Performance testing
Functionality isn’t the only aspect of quality that matters. Performance can make or break user experience. Most people expect any given page to load in a second or two. Back in 2016, Google discovered that half of all people leave a site if it takes longer than 3 seconds to load. As an industry, we’ve put in so much work to make the front end faster. Modern techniques like server-side rendering, hydration, and bloat reduction all aim to improve response times. It’s important to test the performance of our pages to make sure the user experience is tight.
Thankfully, performance testing is easier than ever before. There’s no excuse for not testing performance when it is so vital to success. There are many great ways to get started.
The simplest approach is right in your browser. You can profile any site with Chrome DevTools. Just right click the page, select “Inspect,” and switch to the Performance tab. Then start the profiler and start interacting with the page. Chrome DevTools will capture full metrics as a visual time series so you can explore exactly what happens as you interact with the page. You can also flip over to the Network tab to look for any API calls that take too long. If you want to learn more about this type of performance analysis, Test Automation University offers a course entitled Tools and Techniques for Performance and Load Testing by Amber Race. Amber shows how to get the most value out of that Performance tab.
Chrome DevTools Performance tab
Another nifty tool that’s also available in Chrome DevTools is Google Lighthouse. Lighthouse is a website auditor. It scores how well your site performs for performance, accessibility, progressive web apps, SEO, and more. It will also provide recommendations for how to improve your scores right within its reports. You can run Lighthouse from the command line or as a Node module instead of from Chrome DevTools as well.
Google Lighthouse from Chrome DevTools
Using Chrome DevTools manually for one-off checks or exploratory testing is helpful, but regular testing needs automation. One really cool way to automate performance checks is using Playwright, the end-to-end test framework I mentioned earlier. In Playwright, you can create a Chrome DevTools Protocol session and gather all the metrics you want. You can do other cool things with profiling and interception. It’s like a backdoor into the browser. Best of all, you could gather these metrics together with functional testing! One framework can meet the needs of both functional and performance test automation.
There’s another curve ball when testing websites: what about machine learning models? For example, whenever you shop at an online store, the bottom of almost every product page has a list of recommendations for similar or complementary products. For example, when I searched Amazon for the latest Pokémon video game, Amazon recommended other games and toys:
Recommendation systems like this might be hard-coded for small stores, but large retailers like Amazon and Walmart use machine learning models to back up their recommendations. Models like this are notoriously difficult to test. How do we know if a recommendation is “good” or “bad”? How do I know if folks who like Pokémon would be enticed to buy a Kirby game or a Zelda game? Lousy recommendations are a lost business opportunity. Other models could have more serious consequences, like introducing harmful biases that affect users.
Machine learning models need separate approaches to testing. It might be tempting to skip data validation because it’s harder than basic functional testing, but that’s a risk not worth taking. To do testing right, separate the functional correctness of the frontend from the validity of data given to it. For example, we could provide mocked data for product recommendations so that tests would have consistent outcomes for verifying visuals. Then, we could test the recommendation system apart from the UI to make sure its answers seem correct. Separating these testing concerns makes each type of test more helpful in figuring out bugs. It also makes machine learning models faster to test, since testers or scripts don’t need to navigate a UI just to exercise them.
If you want to learn more about testing machine learning courses, Carlos Kidman created an excellent course all about it on Test Automation University named Intro to Testing Machine Learning Models. In his course, Carlos shows how to test models for adversarial attacks, behavioral aspects, and unfair biases.
#6. JavaScript
Now, the next trend I see will probably be controversial to many of you out there: JavaScript isn’t everything. Historically, JavaScript has been the only language for front end web development. As a result, a JavaScript monoculture has developed around the front end ecosystem. There’s nothing inherently wrong with that, but I see that changing in the coming years – and I don’t mean TypeScript.
In recent years, frustrations with single-page applications (SPAs) and client-heavy front ends have spurred a server-side renaissance. In addition to JavaScript frameworks that support SSR, classic server-side projects like Django, Rails, and Laravel are alive and kicking. Folks in those communities do JavaScript when they must, but they love exploring alternatives. For example, HTMX is a framework that provides hypertext directives for many dynamic actions that would otherwise be coded directly in JavaScript. I could use any of those classic web frameworks with HTMX and almost completely avoid JavaScript code. That makes it easier for programmers to make cool things happen on the front end without needing to navigate a foreign ecosystem.
Below is an example snippet of HTML code with HTMX attributes for posting a click and showing the response:
<script src="https://unpkg.com/htmx.org@1.7.0"></script>
<!-- have a button POST a click via AJAX -->
<button hx-post="/clicked" hx-swap="outerHTML">
Click Me
</button>
WebAssembly, or “Wasm” is also here. WebAssembly is essentially an assembly language for browsers. Code written in higher-level languages can be compiled down into WebAssembly code and run on the browser. All major browsers now support WebAssembly to some degree. That means JavaScript no longer holds a monopoly on the browser.
I don’t know if any language will ever dethrone JavaScript in the browser, but I predict that browsers will become multilingual platforms through WebAssembly in the coming years. For example, at PyCon 2022, Anaconda announced PyScript, a framework for running Python code in the browser. Blazor enables C# code to run in-browser. Emscripten compiles C/C++ programs to WebAssembly. Other languages like Ruby and Rust also have WebAssembly support.
Regardless of what happens inside the browser, black-box testing tools and frameworks outside the browser can use any language. Tools like Playwright and Selenium support languages other than JavaScript. That brings many more people to the table. Testers shouldn’t be forced to learn JavaScript just to automate some tests when they already know another language. This is happening today, and I don’t expect it to change.
#7. Autonomous testing
Finally, there is one more trend I want to share, and this one is more about the future than the present: autonomous testing is coming. Ironically, today’s automated testing is still manually-intensive. Someone needs to figure out features, write down the test steps, develop the scripts, and maintain them when they inevitably break. Visual testing makes verification autonomous because assertions don’t need explicit code, but figuring out the right interactions to exercise features is still a hard problem.
I think the next big advancement for testing and automation will be autonomous testing: tools that autonomously look at an app, figure out what tests should be run, and then run those tests automatically. The key to making this work will be machine learning algorithms that can learn the context of the apps they target for testing. Human testers will need to work together with these tools to make them truly effective. For example, one type of tool could be a test recommendation engine that proposes tests for an app, and the human tester could pick the ones to run.
Autonomous testing will greatly simplify testing. It will make developers and testers far more productive. As an industry, we aren’t there yet, but it’s coming, and I think it’s coming soon. I delivered a keynote address on this topic at Future of Testing: Frameworks 2022:
Conclusion
There’s lots of exciting stuff happening in the world of the front end. As I said before, tools and technologies may change, but fundamentals remain the same. Each of these trends is rooted in tried-and-true principles of testing. They remind us that software quality is a multifaceted challenge, and the best strategy is the one that provides the most value for your project.
So, what do you think? Did I hit all the major front end trends? Did I miss anything? Let me know in the comments!
This article introduces visual testing as a technique that can revolutionize software quality assurance (QA) practices. It is based on a talk I delivered on June 9, 2022 at AITP-RTP, and its target audience includes IT professionals and leaders who may not be hands-on with testing, coding, or automation.
Visual testing techniques are an incredible way to maximize the value of your functional tests. Instead of checking traditional things like text or attributes, visual testing captures full snapshots of your application’s pages and looks for visual differences over time. This isn’t just another nice-to-have feature that’s on the bleeding edge of technology. It’s a tried-and-true technique that anyone can use, and it makes testing easier!
In this article, I want to “open your eyes” to see how visual testing can revolutionize how you approach software quality. I want you to see things in new ways, and I’ll cover five key advantages of visual testing. I’ll use Applitools as the visual testing tool for demonstration. And don’t worry, everything will be high-level – I’ll be light on the code.
What is software testing?
We all know that there are several different kinds of testing. Here’s a short list:
Unit
Integration
End-to-End
Web UI
REST API
Mobile
Load testing
Performance testing
Property-based testing
Behavior-driven
Data-driven
You name it, there’s a test for it. We could play buzzword bingo if we wanted. But what is “testing”? In simplest terms, testing = interaction + verification. That’s it! You do something, and you make sure it works. Every kind of testing reduces to this formula.
We’ve been testing software since the dawn of computers. The “first computer bug” happened on September 9, 1947, when a moth flew into one of the relays of the Mark II computer at Harvard University. What you’re seeing here is Grace Hopper’s bug report, with the dead moth taped onto the notebook page.
Historically, all testing was done manually. Whether it was Grace Hopper pulling a dead moth out of computer relays with tweezers or someone banging on a keyboard to navigate through a desktop app, humans have driven testing. Manual testing was practically the only way to do testing for decades. As applications became more user-centric with the rise of PCs in the 1980s, testing became a much more approachable discipline. Folks didn’t need to hold computer science degrees or to be software engineers to be successful – they just needed common sense and grit. Companies built entire organizations for testers. Releases wouldn’t ship until QA gave them seals of approval. Test repositories could have hundreds, even thousands, of test procedures.
Unfortunately, manual testing does not scale very well. It’s a slow process. If you want to test an app, you need to set everything up, log in, and exercise all the different features. Any time you discover a problem, you need to stop, investigate, and write a report. Every time there’s a new development build, you need to do it all over again. The only way to scale is to hire more testers. Even with more people, testing cycles could take days, weeks, or even months. When I worked at NetApp, the main functional testing phase for a major release took over half a year to complete.
Manual testing is a great way to test software features because it is simple and sensible, but it doesn’t scale well.
The rise of automation
Then, automation came. It started becoming popular with unit testing for functions and methods directly in the code itself in the late 1990s, but then black box automation tools and frameworks started becoming popular in the mid 2000s. Instead of manually performing test cases step by step, testers would write scripts to automatically execute test steps.
Tools like Selenium made it possible to automate browser interactions for testing web apps. Folks could code Selenium calls using the programming language of their choice: Java, JavaScript, C#, Python, Ruby, or PHP. Later, frameworks like Cypress and Playwright refined the experience that Selenium started. Other tools like SoapUI and (later) Postman made it easy to peel back frontend layers and test APIs directly. Appium made it possible to automate tests for mobile apps. So many solutions hit the market. The ones here are only a few. (Please don’t hate me if I didn’t mention your favorite tool here!) Many were free and open source, while others were licensed software products.
Automation offered several benefits over manual testing. With automation, you could run tests more quickly. Scripts don’t need to wait for humans to react to pages or write down results. You could also run tests more frequently. Teams started running tests continuously – nightly at first, and then after every code change. These benefits enabled teams to widen their test coverage and provide faster feedback. Testing work that would take a full team days to complete could be finished in a matter of hours, if not minutes. Test results would be posted in real time instead of at the end of testing cycles. Instead of endlessly executing tests manually, testers gained time back to work on other things, like automating even more tests or doing exploratory testing activities.
Popular test automation tools
Challenges with automation
Unfortunately, it wasn’t all rainbows and unicorns. Test automation was hard to develop. Since it was inherently more complex than manual testing, it required more skills. Testers needed to learn how to use tools like Selenium or Postman. On top of that, they needed to learn how to do programming. If they wanted to use codeless tools instead, then their companies probably had to shell out a pretty penny for licenses. Regardless of the tools chosen, automated scripts could never be made perfect. They are inherently fragile because they depend directly upon the features under test. For example, if a button on a web page changes, then the script will crash. Automated tests also gained a reputation for being flaky when testers didn’t appropriately handle waiting for things on the page to load. Furthermore, automation was only suitable for checking low-level things like text and numbers. That’s fine for unit tests and API tests, but it’s not suitable for user interfaces that are inherently visual. Passing tests could miss a lot of problems, giving a false sense of security.
When considering all these challenges together, we discovered as an industry that test automation isn’t fully autonomous. Despite dreaming of testing-made-easy, automation just made things harder. Teams who could build good test automation projects reaped handsome returns, but for many, the bar was too high. It was out of reach. Many tried and failed. Trust me, I’ve talked with lots of folks who struggle with test automation.
What we really want is the best of both worlds. We want the simplicity and sensibility of manual testing, but with the speed and scalability of automated testing. To get both, most teams use a split testing strategy. They automate some tests while running others manually. Actually, I’ve commonly seen teams run all their tests manually and then automate whatever they can with the time they have left. Some teams are more forward with their automation work, but not all. Folks perpetually make tradeoffs.
But, what if there was a way to get the simplicity and sensibility of manual testing with automation? What if automation could visually inspect our applications for differences like a human could?
Walking through an example
Consider a basic web application with a standard login page:
When we look at this from top to bottom, we see:
A logo
A page title
A username field
A password field
A sign-in button
A remember-me checkbox
Links to social media
However, during the course of development, we know things change – for better or worse. Here’s a different version of the same page:
Can you spot the differences? Looking at these two pages side-by-side makes comparison easier:
The logos are different, and the sign-in buttons are different. While I’d probably ask the developers about the sign-in button change, I’d categorically consider that logo change a bug. My gut tells me a human tester would catch these differences if they were paying attention, but there’s a chance they could miss them. Traditional automation would most likely fly right by these changes without stopping.
In fact, pages can be radically broken visually yet still have passing automated tests. In this version, I stripped all the CSS off the page:
We would definitely call this page broken. A traditional functional test script hinges on the most basic functionality of web pages, like IDs and element attributes. If it clicks, it works! It completely misses visuals. I even wrote a short test script with basic assertions, and sure enough, it passed on all three versions of this login page. Those are huge test gaps.
The magic of visual testing
So, what if we could visually inspect this page with automation? That would easily catch any changes that human eyes would detect, but with speed and scale. We could take a baseline snapshot that we consider “good,” and every time we run our tests, we take a new “checkpoint” snapshot. Then, we can compare the two side-by-side to detect any changes. This is what we call visual testing: take a baseline snapshot to start, take a checkpoint snapshot after every change, and look for any visual differences programmatically. If a picture is worth a thousand words, then a snapshot is worth a thousand assertions.
Visual testing: identifying differences between baseline snapshots to checkpoint snapshots.
One visual snapshot captures everything on the page. As a tester, you don’t need to explicitly state what to check: a snapshot implicitly covers layout, color, size, shape, and styling. That’s a huge advantage over traditional functional test automation.
Visual Testing Advantage #1:
Visual testing covers everything on a page.
Unfortunately, not all visual testing techniques are created equal. Programming a tool to capture snapshots and perform pixel-by-pixel comparisons isn’t too difficult, but determining if those changes matter is very difficult. A good visual testing tool should ignore changes that don’t matter – like small padding differences – and focus on changes that do matter – like missing elements. Otherwise, human testers will need to review every single result, nullifying any benefit of automating visual tests.
Take a look at these two pictures. They show a cute underwater scene. There are a total of ten differences between the two pictures. Can you find them?
Unfortunately, a pixel-to-pixel comparison won’t find any of them. I ran these two pictures through Applitools Eyes using an exact pixel-to-pixel comparison, and this is what happened:
Except for the whitespace on the sides, every pixel was different. As humans, we can clearly see that these images are very similar, but because they were a few pixels off on the sides, automation failed to pinpoint meaningful differences.
This is where AI really helps. Applitools uses Visual AI to detect meaningful changes that humans would see and ignore inconsequential differences that just make noise. Here, I used Applitools’ “strict” comparison, which pinpointed each of the ten differences:
That’s the second advantage of good automated visual testing: Visual AI focuses on meaningful changes to avoid noise. Visual test results shouldn’t waste testers’ time over small pixel shifts or things a human wouldn’t even notice. They should highlight what matters, like missing elements, different colors, or skewed layouts. Visual AI is a differentiator for visual testing tools. Not all tools rise above pixel-to-pixel comparisons.
Visual Testing Advantage #2:
Visual AI focuses on meaningful changes to avoid noise.
Simplifying test cases
Now, there are two main ways to automate tests. One path is to use coded tools. Tools like Selenium WebDriver are “coded” tools because they require testers to call them directly from programming code. Selenium WebDriver has bindings in Java, JavaScript, C#, Python, or Ruby, so testers can pick the language of their choice. Nevertheless, testers must essentially be developers to use coded tools.
The second path to automation is using codeless tools. Codeless tools don’t require testers to have programming skills. Instead, they record testers as they exercise features under test, and then they can replay those recorded tests at the push of a button. Most codeless tools also have some sort of visual builder through which testers can tweak and update their tests. There are several codeless tools available on the market, and many of them require paid licenses. However, Selenium IDE is a free and open source tool that does the job quite nicely.
Coded and codeless tools serve different needs. Coded tools are great for folks like me who know how to code and want high-power, customizable automation. Codeless tools are great for teams that are just getting started with automation, especially when most of their testing has historically been done manually. Regardless of approach, the good news is that you can do visual testing either way! For example, if you use Applitools, then there are SDKs and integrations for many different tools and frameworks.
As we recall, testing is interaction plus verification. When automating tests, the interactions and the verifications are scripted using either a coded or codeless tool. Testers must specify each of those operations. For example, if a test is exercising login behavior on this login page:
Then the interactions would be:
Loading the page
Entering username
Entering password
Clicking the login button
Waiting for the main page to load
And then, the verifications would be checking that the main page loads correctly:
As we can see, this main page has lots of stuff on it. We could check several things:
The title bar at the top
The side bar with different card types and lending options
The warning message about nearby branches closing soon
The values in the financial overview
The table of recent transactions
But, what should we check? The more things we verify in a test, the more coverage the test will have. However, the test will take longer to develop, require more time to run, and have a higher risk of breaking as development proceeds.
I wrote some Java code to perform high-level assertions on this page:
// Check various page elements
waitForAppearance(By.cssSelector("div.logo-w"));
waitForAppearance(By.cssSelector("div.element-search.autosuggest-search-activator > input"));
waitForAppearance(By.cssSelector("div.avatar-w img"));
waitForAppearance(By.cssSelector("ul.main-menu"));
waitForAppearance(By.xpath("//a/span[.='Add Account']"));
waitForAppearance(By.xpath("//a/span[.='Make Payment']"));
waitForAppearance(By.xpath("//a/span[.='View Statement']"));
waitForAppearance(By.xpath("//a/span[.='Request Increase']"));
waitForAppearance(By.xpath("//a/span[.='Pay Now']"));
// Check time message
assertTrue(Pattern.matches(
"Your nearest branch closes in:( \\d+[hms])+",
driver.findElement(By.id("time")).getText()));
// Check menu element names
var menuElements = driver.findElements(By.cssSelector("ul.main-menu li span"));
var menuItems = menuElements.stream().map(i -> i.getText().toLowerCase()).toList();
var expected = Arrays.asList("card types", "credit cards", "debit cards", "lending", "loans", "mortgages");
assertEquals(expected, menuItems);
// Check transaction statuses
var statusElements = driver.findElements(By.xpath("//td[./span[contains(@class, 'status-pill')]]/span[2]"));
var statusNames = statusElements.stream().map(n -> n.getText().toLowerCase()).toList();
var acceptableNames = Arrays.asList("complete", "pending", "declined");
assertTrue(acceptableNames.containsAll(statusNames));
If you don’t know Java, please don’t be frightened by this code! It checks that certain elements and links appear, that the warning message displays a timeframe, and that correct names for menu items and transaction statuses appear. As you can see, that’s a lot of complicated code – and that’s what I want you to see.
Sadly, its coverage is quite shallow. This code doesn’t check the placement of any elements. It doesn’t check the title bar, the financial overview values, or any transaction values other than status. If I wanted to cover all these things, I’d probably need to add at least another hundred lines of code. That might take me an hour to find all the locators, parse the text values, and run it a few times to make sure it works. Someone else would need to do a code review before the changes could be merged, as well.
If I do visual testing, then I could eliminate all this code with a one-line snapshot call:
As an engineer, I cannot overstate how much this simplifies test development. A single snapshot implicitly covers everything on the page: visuals, text, placement, and color. I don’t need to make tradeoffs about what to check and what not to check. Visual snapshots remove a tremendous cognitive burden. They improve test coverage and make tests more robust. This is the same whether you are using a coded tool like Selenium WebDriver in Java or a codeless tool like Selenium IDE.
This is the third major advantage visual testing has over traditional functional testing: visual snapshots greatly simplify assertions. Instead of spending hours deciding what to check, figuring out locators, and writing transformation logic, you can make one concise snapshot call and be done. I said it before, and I’ll say it again: If a picture is worth a thousand words, then a snapshot is worth a thousand assertions.
Visual Testing Advantage #3:
A snapshot is worth a thousand assertions.
Testing different browsers and devices
So, what about cross-browser and cross-device testing? It’s great if my app works on my machine, but it also needs to work on everyone else’s machine. The major browsers these days are Chrome, Edge, Firefox, and Safari. The two main mobile platforms are iOS and Android. That might not sound like too much hassle at first, but then consider:
All the versions of each browser – typically, you want to verify that your app works on the last two or three releases.
All the screen sizes – modern web apps have responsive designs that change based on viewport.
All the device types – desktops and laptops have various operating systems, and phones and tablets come in a plethora of models.
We have a combinatorial explosion! Traditional functional tests must be run start-to-finish in their entirety on each of these platforms. Most teams will pick a few of the most popular combinations to test and skip the rest, but that could still require lots of test execution.
Visual testing simplifies things here, too. We already know that visual testing captures snapshots of pages in our applications to look for differences over time. Note how I used the word “snapshot” and not “screenshot.” That was deliberate. A screenshot is merely a rasterized capture of pixels reflecting an instantaneous view. It’s frozen in time and in size. A snapshot, however, captures everything that makes up the page: the HTML structure, the CSS styling, and the JavaScript code that brings it to life.
With cross-platform visual testing, a snapshot can be captured once and then re-rendered on any browser or device configuration.
Snapshots are more powerful than screenshots because snapshots can be re-rendered. For example, I could run my test one time on my local machine using Google Chrome, and then I could re-render any snapshots I capture from that test on Firefox, Safari, or Edge. I wouldn’t need to run the test from start to finish three more times – I just need to re-render the snapshots in the new browsers and run the Visual AI checker. I could re-render them using different versions and screen sizes, too, because I have the full page, not just a flat screenshot. This works for web apps as well as mobile apps.
Visually-based cross-platform testing is lightning fast. A typical UI test case takes about a minute to run. It could be more or less, but from my experience, 1 minute is a rough industry average. A visual checkpoint backed by Visual AI takes only a few seconds to complete. Do the math: if you have a large test suite with hundreds to thousands of tests that you need to test across multiple configurations, then visual testing could save you hours, if not days, of test execution time per cycle. Plus, if you use a service like Applitools Ultrafast Test Cloud, then you won’t need to set up all those different configurations yourself. You’ll spend less time and money on your full test efforts.
There is one more thing I want y’all to consider: when should a team adopt visual testing into their quality strategy? I can’t tell you how many times folks have told me, “Andy, that visual testing thing looks so cool and so helpful, but I don’t think my team will ever get there. We’re just getting started, and we’re new to automation, and automation is so hard, and I don’t think we’ll ever be mature enough to adopt visual testing techniques.” Every time I hear these reasons, I can’t help but do a facepalm.
Visual snapshots cover more of a view than traditional assertions ever could.
Visual AI ensures that any visual differences identified are important.
Re-rendering snapshots on different configurations simplifies cross-platform testing.
I really think teams should do visual testing from the start. Consider this strategy: start by automating a few basic tests that navigate to different pages of an app and capture snapshots of each. The interactions would be straightforward, and the verifications would be single-step one-liners. If the testers are new to automation, they could go codeless with Selenium IDE just to get started. That would provide an immense amount of value for relatively little automation work. It’s the 80/20 rule: 80% of the value for 20% of the work. Then, later, when the team has more time or more maturity, they can expand the automation project with larger tests that use both traditional and visual assertions.
Visual Testing Advantage #5:
Visual testing makes functional testing easier.
Test automation is hard, no matter what tool or what language you use. Teams struggle to automate tests in time and to keep them running. Visual testing simplifies implementation and execution while catching more problems. It offers the advantage of making functional testing easier. It’s not a technique only for those on the bleeding edge. It’s here today, and it’s accessible to anyone doing test automation.
Next Steps
Overall, visual testing is a winning strategy. It has several advantages over traditional functional testing. Please note, however, that visual testing does not replace functional testing. Instead, it supercharges it. With a visual testing tool like Applitools Eyes, you can do visual testing in any major language or test framework you like, and with Applitools Ultrafast Test Cloud, you can do visual testing using any major browser or mobile configuration.
If you want to give visual testing a try with Applitools, start by registering a free account. Then, take of one of the Applitools tutorials. You can pick a tutorial for any of the supported SDKs. If you get stuck and need help, just contact me – I’ll be more than happy to help!
I’m super excited to introduce a somewhat new idea to you and to our industry: Open Testing: What if we open our tests like we open our source? I’m not merely talking about creating open source test frameworks. I’m talking about opening the tests themselves. What if it became normal to share test cases and automated procedures? What if it became normal for companies to publicly share their test results? And what are the degrees of openness in testing for which we should strive as an industry?
I think that we – whether we are testers, developers, managers, or any other role in software – can greatly improve the quality of our work if we adopt principles of openness into our testing practices. To help me explain, I’d like to share how I learned about the main benefits of open source software, and then we can cross those benefits over into testing work.
So, let’s go way back in time to when I first encountered open source software.
My first encounter with open source code
I first started programming when I was in high school. At 13 years old, I was an incoming freshman at Parkville High School in their magnet school for math, science, and computer science in good old Baltimore, Maryland. (Fun fact: Parkville’s mascots were the Knights, which is my last name!) All students in the magnet program needed to have a TI-83 Plus graphing calculator. Now, mind you, this was back in the day before smart phones existed. Flip phones were the cool trend! The TI-83 Plus was cutting-edge handheld technology at that time. It was so advanced that when I first got it, it took me 5 minutes to figure out how to turn it off!
The TI-83 Plus
I quickly learned that the TI-83 Plus was just a mini-computer in disguise. Did you know that this thing has a full programming language built into it? TI-BASIC! Within the first two weeks of my freshman Intro to Computer Science class, our teacher taught us how to program math formulas: Slope. Circle circumference and area. The quadratic formula. You name it, I programmed it, even if it wasn’t a homework assignment. It felt awesome! It was more fun to me than playing video games, and believe me, I was a huge Nintendo fan.
There were two extra features of the TI-83 Plus that made it ideal for programming. First, it had a link cable for sharing programs. Two people could connect their calculators and copy programs from one to the other. Needless to say, with all my formulas, I became quite popular around test time. Second, anyone could open any program file on the calculator and read its code. The TI-BASIC source code could not be hidden. By design, it was “open source.”
This is how I learned my very first lesson about open source software: Open source helps me learn. Whenever I would copy programs from others, including games, I would open the program and read the code to see how it worked. Sometimes, I would make changes to improve it. More importantly, though, many times, I would learn something new that would help me write better programs. This is how I taught myself to code. All on this tiny screen. All through ripping open other people’s code and learning it. All because the code was open to me.
From the moment I wrote my first calculator program, I knew I wanted to become a software engineer. I had that spark.
My first open source library
Let’s fast-forward to college. I entered the Computer Science program at Rochester Institute of Technology – Go Tigers! By my freshman year in college, I had learned Java, C++, a little Python, and, of all things, COBOL. All the code in all my projects until that point had been written entirely by me. Sometimes, I would look at examples in books as a guide, but I’d never use other people’s code. In fact, if a professor caught you using copied code, then you’d fail that assignment and risk being expelled from the school.
Then, in my first software engineering course, we learned how to write unit tests using a library called JUnit. We downloaded JUnit from somewhere online – this was before Maven became big – and hooked it into our Java path. Then, we started writing test classes with test case methods, and somehow, it all ran magically in ways I couldn’t figure out at the time.
I was astounded that I could use software that I didn’t write myself in a project. Permission from a professor was one thing, but the fact that someone out there in the world was giving away good code for free just blew my mind. I saw the value in unit tests, and I immediately saw the value in a simple, free test framework like JUnit.
That’s when I learned my second lesson about open source software: Open source helps me become a better developer. I could have written my own test framework, but that would have taken me a lot of time. JUnit was ready to go and free to use. Plus, since several individuals had already spent years developing JUnit, it would have more features and fewer bugs than anything I could develop on my own for a college project. Using a package like JUnit helped me write and run my unit tests without needing to become an expert in test automation frameworks. I could build cool things without needing to build every single component.
That revelation felt empowering. Within a few years of taking that software engineering course, sites for hosting open source projects like GitHub became huge. Programming language package indexes like Maven, NuGet, PyPI, and NPM became development mainstays. The running joke within Python became that you could import anything! This was way better than swapping calculator games with link cables.
My first chance to give back
When I graduated college, I was zealous for open source software. I believed in it. I was an ardent supporter. But, I was mostly a consumer. As a Software Engineer in Test, I used many major test tools and frameworks: JUnit, TestNG, Cucumber, NUnit, xUnit.net, SpecFlow, pytest, Jasmine, Mocha, Selenium WebDriver, RestSharp, Rest Assured – the list goes on and on. As a Python developer, I used many modules and frameworks in the Python ecosystem like Django, Flask, and requests.
Then, I got the chance to give back: I launched an open source project called Boa Constrictor. Boa Constrictor is a .NET implementation of the Screenplay Pattern. It helps you make better interactions for better automation. Out of the box, it provides Web UI interactions using Selenium WebDriver and Rest API interactions using RestSharp, but you can use it to implement any interactions you want.
My company and I released Boa Constrictor publicly in October 2020. You can check out the boa-constrictor repository on GitHub. Originally, my team and I at Q2 developed all the code. We released it as an open source project hoping that it could help others in the industry. But then, something cool happened: folks in the industry helped us! We started receiving pull requests for new features. In fact, we even started using some new interactions developed by community members internally in our company’s test automation project. We also proudly participated in Hacktoberfest in 2020 and 2021.
Boa Constrictor: The .NET Screenplay Pattern
That’s when I learned my third lesson about open source software: Open source helps me become a better maintainer. Large projects need all the help they can get. Even a team of core maintainers can’t always handle all the work. However, when a project is open source, anyone who uses it can help out. Each little contribution can add value for the whole user base. Maintaining software then becomes easier, and the project can become more impactful.
Struggling with poor quality
As a Software Engineer in Test, I found myself caught between two worlds. In one world, I was a developer at heart who loved to write code to solve problems. In the other world, I was a software quality professional who tested software and advocated for improvements. These worlds came together primarily through test automation and continuous integration. Now that I’m a developer advocate, I still occupy this intersectionality with a greater responsibility for helping others.
However, throughout my entire career, I keep hitting one major problem: Software quality has a problem with quality. Let that sink in: software quality has a big problem with quality. I’ve worked on teams with titles ranging from “Software Quality Assurance” to “Test Engineering & Architecture,” and even an “Automation Center of Excellence.” Despite the titular focus on quality, every team has suffered from aspects of poor quality in workmanship.
Here are a few poignant examples:
Manual test case repositories are full of tests with redundant steps.
Test automation projects are riddled with duplicate code.
Setup and cleanup steps are copy-pasted endlessly, whether needed or not.
Automation code uses poor practices, such as global variables instead of dependency injection.
A 90% success rate is treated as a “good” day with “limited” flakiness.
Many tests cover silly, pointless, or unimportant things instead of valuable, meaningful behaviors.
How can we call ourselves quality professionals when our own work suffers from poor quality? Why are these kinds of problems so pervasive? I think they build up over time. Copy-pasting one procedure feels innocuous. One rogue variable won’t be noticed. One flaky test is no big deal. Once this starts happening, teams insularly keep repeating these practices until they make a mess. I don’t think giving teams more time to work on these problems will solve them, either, because more time does not interrupt inertia – it merely prolongs it.
The developer in me desperately wants to solve these problems. But how? I can do it in my own projects, but because my tests are sealed behind company doors, I can’t use it to show others how to do it at scale. Many of the articles and courses we have on how-to-do-X are full of toy examples, too.
Changing our quality culture
So, how do we get teams to break bad habits? I think our industry needs a culture change. If we could be more open with testing like we are open with source code, then perhaps we could bring many of the benefits we see from open source into testing:
Helping people learn testing
Helping people become better testers
Helping people become better test maintainers
If we cultivate a culture of openness, then we could lead better practices by example. Furthermore, if we become transparent about our quality, it could bolster our users’ confidence in our products while simultaneously keeping us motivated to keep quality high.
There are multiple ways to start pursuing this idea of open testing. Not every possibility may be applicable for every circumstance, but my goal is to get y’all thinking about it. Hopefully, these ideas can inspire better practices for better quality.
Openness through internal collaboration
For a starting point of reference, let’s consider the least open context for testing. Imagine a team where testing work is entirely siloed by role. In this type of team, there is a harsh line between developers and testers. Only the testers ever see test cases, access test repositories, or touch automation. Test cases and test plans are essentially “closed” to non-testers due to access, readability, or even apathy. The only output from testers are failure percentages and bug reports. Results are based more on trust than on evidence.
This kind of team sounds pretty bleak. I hope this isn’t the kind of team you’re on, but maybe it is. Let’s see how openness can make things better.
The first step towards open testing is internal openness. Let’s break down some siloes. Testers don’t exclusively own quality. Not everyone needs to be a tester by title, but everyone on the team should become quality-conscious. In fact, any software development team has three main roles: Business, Development, and Testing. Business looks for what problems to solve, Development addresses how to implement solutions, and Testing provides feedback on the solution. These three roles together are known as “The Three Amigos” or “The Three Hats.”
Each role offers a valuable perspective with unique expertise. When the Three Amigos stay apart, features under development don’t have the benefit of multiple perspectives. They might have serious design flaws, they might be unreasonable to implement, or they might be difficult to test. Misunderstandings could also cause developers to build the wrong things or testers to write useless tests. However, when the Three Amigos get together, they can jointly contribute to the design of product features. Everyone can get on the same page. The team can build quality into the product from the start. They could do activities like Question Storming and Example Mapping to help them define behaviors.
The Three Amigos
As part of this collaboration, not everyone may end up writing tests, but everyone will be thinking about quality. Testing then becomes easier because expected behaviors are well-defined and well-understood. Testers get deeper insight into what is important to cover. When testers share results and open bugs, other team members are more receptive because the feedback is more meaningful and more valuable.
We practiced Three Amigos collaboration at my previous company, Q2. My friend Steve was a developer who saw the value in Example Mapping. Many times, he’d pick up poorly-defined user stories with conflicting information or missing acceptance criteria. Sometimes, he’d burn a whole sprint just trying to figure things out! Once he learned about Example Mapping, he started setting up half-hour sessions with the other two Amigos (one of whom was me) to better understand user stories from the start. He got into it. Thanks to proactive collaboration, he could develop the stories more smoothly. One time, I remember we stopped working on a story because we couldn’t justify its business value, which saved Steve two weeks of pointless work. The story didn’t end there: Steve became a Software Engineer in Test! He shifted left so hard that he shifted into a whole new role.
Openness through living specs
Another step towards open testing is living documentation through specification by example. Collaboration like we saw with the Three Amigos is great, but the value it provides can be fleeting if it is not written down. Teams need artifacts to record designs, examples, and eventually test cases.
One reason why I love Example Mapping is because it facilitates a team to spell out stories, rules, examples, and questions onto color-coded cards that they can keep for future refinement.
Stories become work items.
Rules become acceptance criteria.
Examples become test cases.
Questions become spikes or future stories.
During Example Mapping, folks typically write cards quickly. An example card describes a behavior to test, but it might not carefully design the scenario. It needs further refinement. Defining behaviors using a clear, concise format like Given-When-Then makes behaviors easy to understand and easy to test.
For example, let’s say we wanted to test a web search engine. The example could be to search for a phrase like”panda”. We could write this example as the following scenario:
Given the search engine page is displayed
When the user searches for the phrase “panda”
Then the results page shows a list of links for “panda”
This special Given-When-Then format is known as the Gherkin language. Gherkin comes from Behavior-Driven Development tools like Cucumber, but it can be helpful for any type of testing. Gherkin defines testable behaviors in a concise way that follows the Arrange-Act-Assert pattern. You set things up, you interact with the feature, and you verify the outcomes.
Furthermore, Gherkin encourages Specification by Example. This scenario provides clear instructions on how to perform a search. It has real data, which is the search phrase “panda,” and clear results. Using real-world examples in specifications like this helps all Three Amigos understand the precise behavior.
Turning Example Mapping cards into Gherkin behavior specs
Behavior specifications are multifaceted artifacts:
They are requirements that define how a feature should behave.
They are acceptance criteria that must be met for a deliverable to be complete.
They are test cases with clear instructions.
They could become automated scripts with the right kind of test framework.
They are living documentation for the product.
Living documentation is open and powerful. Anyone on the team or outside the team can read it to learn about the product. Refining ideas into example cards into behavior specs becomes a pipeline that delivers living doc as a byproduct of the software development lifecycle.
SpecFlow is one of the best frameworks that supports this type of openness with Specification by Example and Living Documentation. SpecFlow is a free and open-source test automation framework for .NET. In SpecFlow, you write your test cases as Gherkin scenarios, and you automate each Given-When-Then step using C# methods.
One of SpecFlow’s niftiest features, however, is SpecFlow+ LivingDoc. Most test frameworks focus exclusively on automation code. When a test is automated, then only a programmer can read it and understand it. Gherkin makes this easier because steps are written in plain language, but Gherkin scenarios are nevertheless stored in a code repository that’s inaccessible to many team members. SpecFlow+ LivingDoc breaks that pattern. It turns Gherkin scenarios into a searchable doc site accessible to all Three Amigos. It makes test cases and test automation much more open. LivingDoc also provides test results for each scenario. Green check marks indicate passing tests, while red X’s indicate failures.
Historically, testers use reports like this to provide feedback in-house to their managers and developers. Results indicate what works and what needs to be fixed. However, test results can be useful to more people than just internal team members. What if test results were shared with users and customers? I’m going to repeat that statement, because it might seem shocking: What if users and customers could see test results?
Think about it. Open test results have very positive effects. Transparency with users builds trust. If users can see that things are tested and working, then they will gain confidence in the quality of the product. If they could peer into the living documentation, then they could learn how to use the product even better. On the flip side, transparency holds development teams accountable to keeping quality high, both in the product and in the testing. Open test results offer these benefits only if the results can be trusted. If tests are useless or failures are rampant, then public test results could actually hurt the ones developing the product.
A SpecFlow+ LivingDoc report
This type of radical transparency would require an enormous culture shift. It may not be appropriate for every company to create public dashboards with their test results, but it could be a strategic differentiator when used wisely. For example, when I worked at Q2, we shared LivingDoc reports with specific PrecisionLender customers after every two-week release. It built trust. Plus, since the LivingDoc report includes only high-level behavior specs with simple results, even a vice president could read it! We could share tests without sharing automation code. That was powerful.
Openness through open source
Let’s keep extending open testing outward. In addition to sharing test results and living documentation, folks can also share tools, frameworks, and other parts of their tests. This is where open testing truly is open source.
We already covered a bunch of open source projects for test automation. As an industry, we are truly blessed with so many incredible projects. Every single one of them represents a team of testers who not only solved a problem but decided to share their solution with the world. Each solution is abstract enough to apply to many circumstances but concrete enough to provide a helpful implementation. Collectively, the projects on this page have probably been downloaded more than a billion times, and that’s no joke. And if you want, you could read the open source code for any of them.
Popular open source test automation projects
Cool new projects appear all the time, too. One of my favorite projects that started in the past few years is Playwright, an awesome browser automation tool from Microsoft. Playwright makes end-to-end web testing easy, reliable, and fast. It provides cross-browser and cross-language support like Selenium, a concise syntax like Cypress, and a bunch of advanced features like automatic waiting, tracing, and code generation. Plus, Playwright is magnitudes faster than other automation tools. It took things that made Selenium, Cypress, and Puppeteer great, and it took them to the next level.
Openness through shared test suites
So far, all the ways of approaching open testing are things we could do today. Many of us are probably already doing these things, even if we didn’t think of them under the phrase “open testing.” But where can these ideas go in the future?
My mind goes back to one of the big problems with testing that I mentioned earlier: duplication. Opening up collaboration fixes some bad habits, and sharing components eliminates some duplication in the plumbing of test automation, but so many of our tests across the industry repeat the same kinds of steps and follow the same types of patterns.
For example, think about any time you’ve ordered something from an online store. It could be Amazon, Walmart, Target – whatever. Every single online store has a virtual shopping cart. Whenever you want to buy something, you add it to your cart. Then, when you’re done shopping, you proceed to pay for all the items in your cart. If you decide you don’t want something anymore, you remove it from the cart. Easy-peasy.
As I describe this type of shopping cart, I don’t need to show you screenshots from the store website to explain it. Y’all have done so much online shopping that you intuitively know how it works, regardless of the store. Heck, I recently ordered a bunch of parts for an old Volkswagen Beetle from a site named JBugs, and the shopping cart was the same.
If so many applications have the same parts, then why do we keep duplicating the same tests in different places? Think about it. Think about how many times different teams have written nearly identical shopping cart tests. Ouch. Think about how much time was wasted on that duplication of effort.
I think this is something where Artificial Intelligence and Machine Learning could help. What if we could develop machine learning models to learn common behaviors for apps and services? The learning agents would look for things like standard icons and typical workflows. We could essentially create test suites for things like login, search, shopping, and payment that could run successfully on most apps. These kinds of tests probably couldn’t cover everything in any given application, but they could cover basic, common behaviors. Maybe that could cover a quarter of all behaviors worth testing. Maybe a third? Maybe half? Every little bit helps!
AI and ML can help us achieve true Autonomous Testing
Now, imagine sharing those generic test suites publicly. In the same way developers have open source projects to help expedite their coding, and in the same way data scientists have open data sets to use for modeling, testers could have open test suites that they could pick up and run as applicable. Not test tools – but actual runnable tests that could run against any application. If these kinds of test suites prove to be valuable, then prominent ones could become universally-accepted bars of quality for software apps. For example, in the future, companies could download and execute tests that run on any system for the apps they’re developing in addition to the tests they develop in-house. I think that could be a really cool opportunity.
This type of testing – Autonomous Testing – is the future. Software developer and testers will use AI-backed tools to better learn, explore, and exercise app behaviors. These tools will make it easier than ever to automate scriptable tests.
How to start pursuing openness
As we have covered, open testing could take many forms:
It could be openness in collaboration to build better quality from the start.
It could be openness in specification by example and living documentation.
It could be openness in sharing tests and their results with customers and users.
It could be openness in sharing tools, frameworks, and platforms.
It could be openness in building shared test sets for common application behaviors.
Some of these ideas might seem far-fetched or aspirational, but quite honestly, I think each of them could add lots of value to testing practices. I think every tester and every team should look at this list and ask themselves, “Could we try some of these things?” Perhaps your team could take baby steps with better collaboration or better specification. Perhaps your team has a cool project you built in-house that you could release as an open source project, like my old team and I did with Boa Constrictor. Perhaps there’s a startup idea in using machine learning for autonomous testing. Perhaps there are other ways to achieve open testing that aren’t listed here. Who knows? It could be cool!
We should also consider the flip side. Are there certain aspects of testing that should remain closed? My mind goes to security. Could fully open testing inadvertently reveal security vulnerabilities? Could lack of coverage in some areas welcome expedited exploitation? I don’t know, but I think we should consider possibilities like these.
If you want to pursue open testing, here are three questions to get you started:
How is your testing today?
In what ways is it already open?
In what ways is it closed?
How could your testing improve with incremental openness?
We’re talking baby steps here – small improvements that you could easily achieve today.
It could be as small as trying Example Mapping or joining a mob programming session.
How could your testing improve with radical openness?
Shoot the moon! Dream big! Get creative!
In the world of software, anything is possible.
Conclusion
We should also remember that open testing isn’t a goal unto itself. It’s a means to an end, and that end is higher quality: quality in our practices, quality in our artifacts, and ultimately quality in the software we create. We shouldn’t seek openness in testing just because I’m spouting lots of buzzwords in this article. At the same time, we also shouldn’t brush off these ideas as too radical or idealistic. What we should do is seek ways for perpetual improvement. Remember that this whole idea of open testing came from the tried-and-true benefits of open source code.






































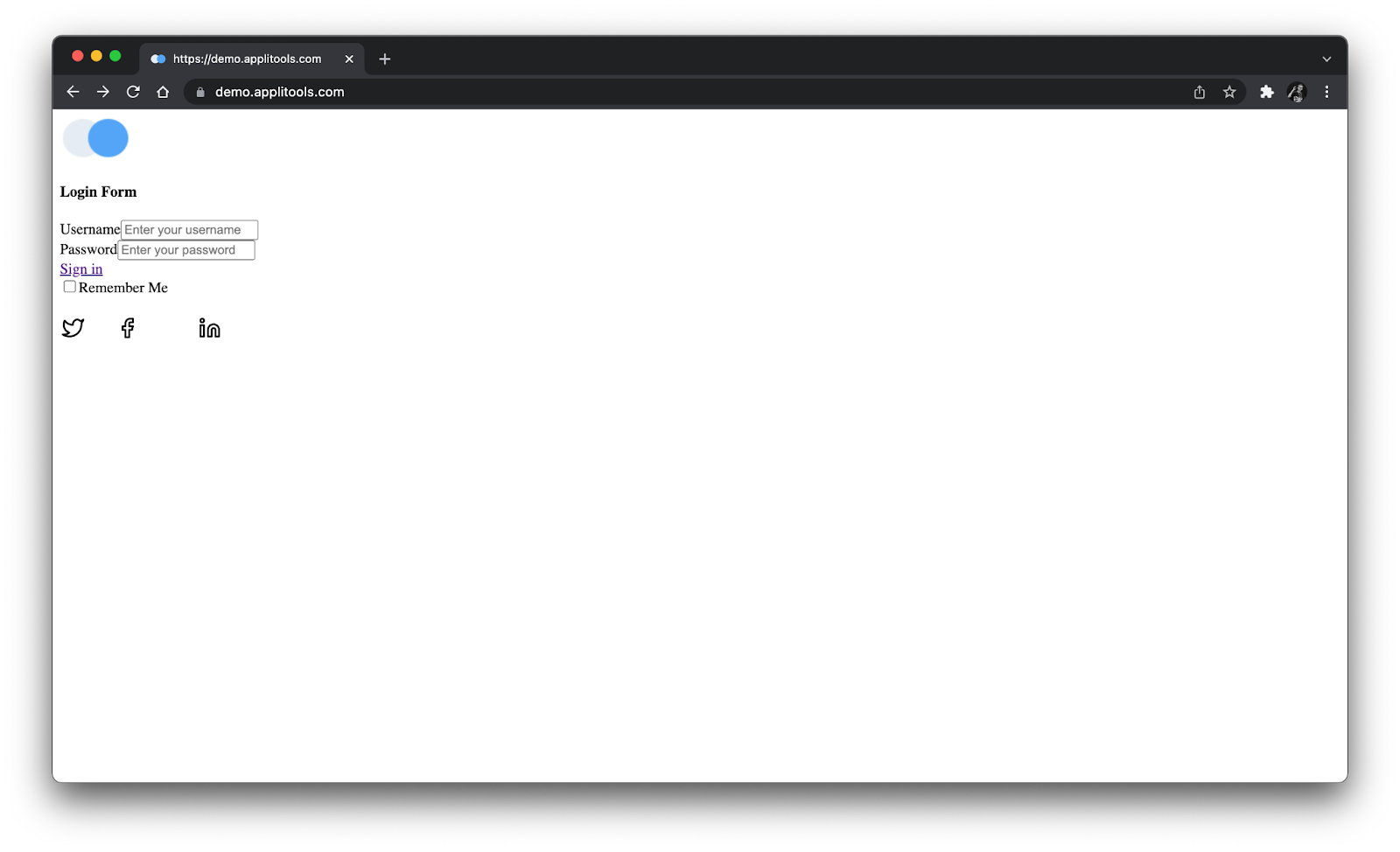

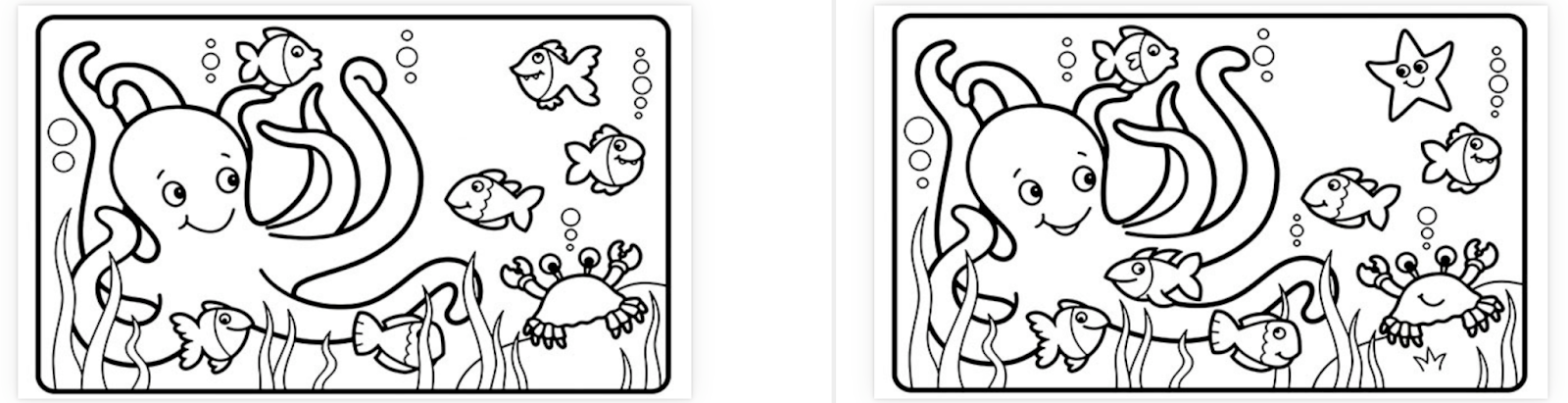
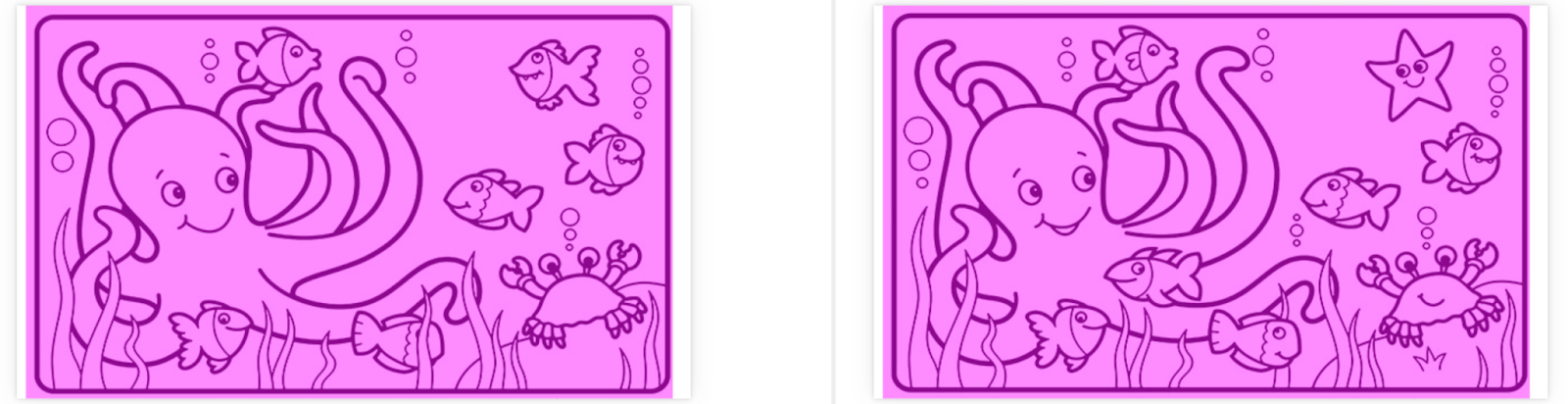
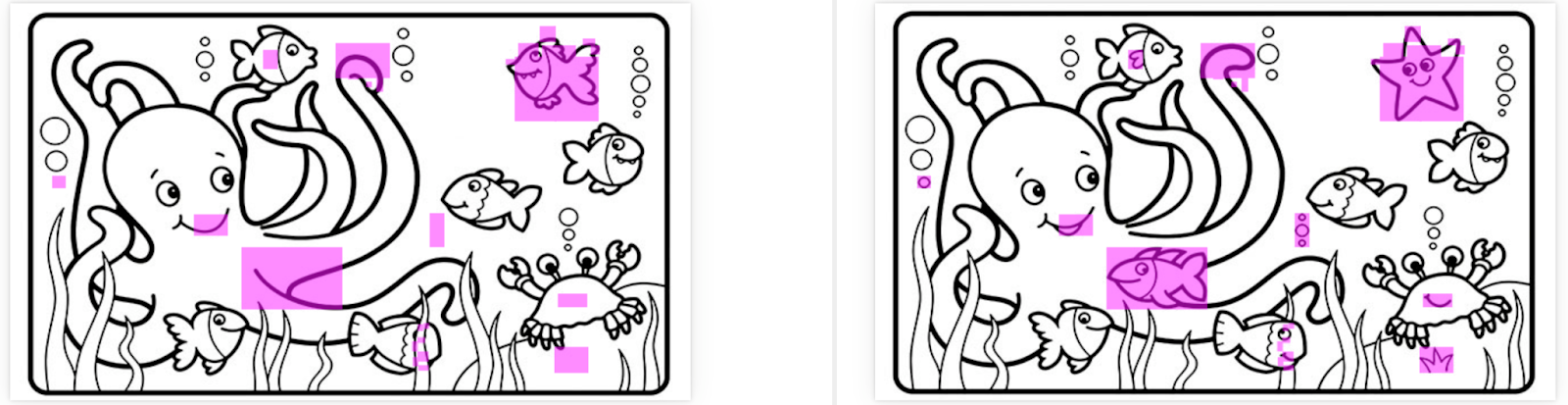
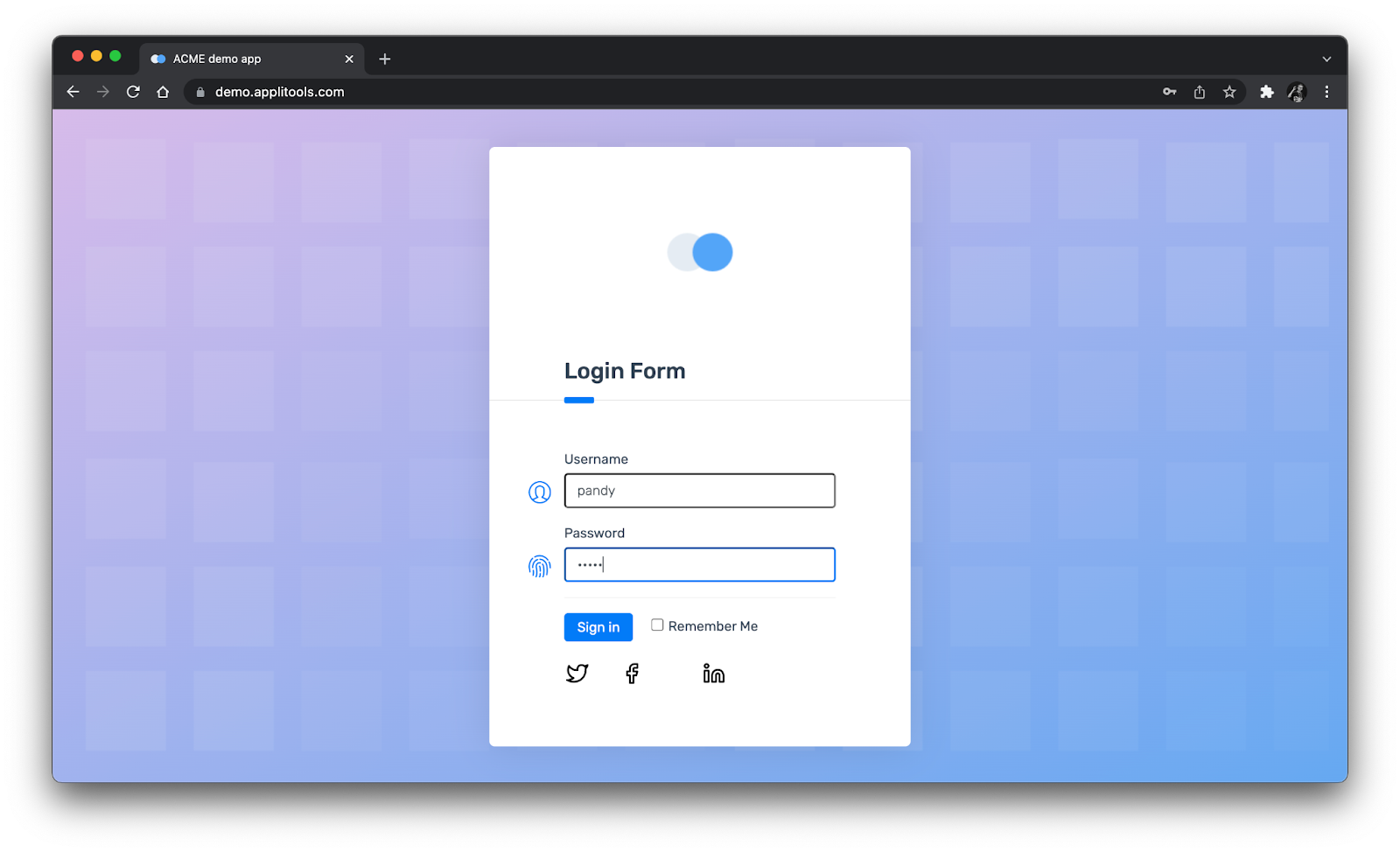
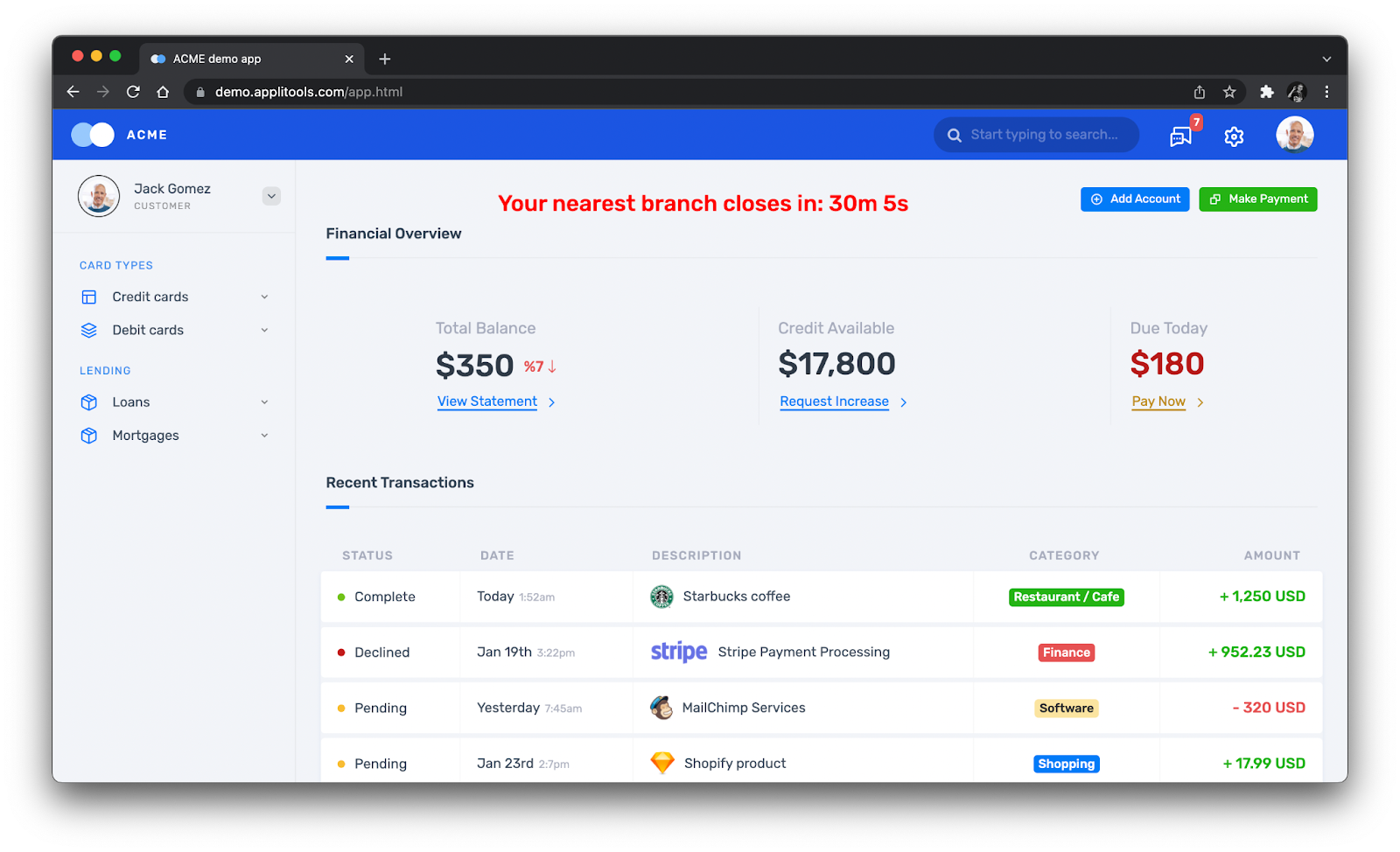











{kind=link}