
Katsushika Hokusai, 1830.
It is one of the most recognizable works of art in the world. It is so famous, it has an emoji: 🌊.
The Great Wave Off Kanagawa is a Japanese woodblock print. It is not a painting or a drawing but a print. In Japanese, the term for this type of art is ukiyo-e, which means “pictures of the floating world.” Ukiyo-e prints first appeared around the 1660s and did not decline in popularity until the Meiji Restoration two centuries later. While most artists focused on subjects of people, late masters like Hokusai captured perspectives of landscapes and nature. Here, in The Great Wave, we see a giant wave, full of energy and ferocity, crashing down onto three fast boats attempting to transport live fish to market. Its vibrant blue water and stark white peaks contrast against a yellowish-gray sky. In the distance is Mount Fuji, the highest mountain in Japan, yet it is dwarfed in perspective by the waves. In fact, the water spray from the waves appears to fall over Mount Fuji like snow. If you didn’t look closely, you might presume that Mount Fuji is just the crest of another wave.
The Great Wave is absolutely stunning. It is arguably Hokusai’s finest work. The colors and the lines reflect boldness. The claws of the wave impart vitality. The men on the boat show submission and possibly fear. The spray from the wave reveals delicacy and attention to detail. Personally, I love ukiyo-e prints like this. I travel the world to see them in person. The quality, creativity, and craftsmanship they exhibit inspire me to instill the highest quality possible into my own work.
As software quality professionals, there are several lessons we can learn from ukiyo-e masters like Hokusai. Testing is an art as much as it is engineering. We can take cues from these prolific artists in how we approach quality in our own work. In this article, I will share how we can make our own “Great Waves” using 8 software testing convictions inspired by ukiyo-e prints like The Great Wave. Let’s begin!
Conviction #1: Focus on behavior
Although we hold these Japanese woodblock prints today in high regard, they were seen as anything but fancy centuries ago in Japan. Ukiyo-e was “low” art for the common people, whereas paintings on silk scrolls were considered “high” art for the high classes.
Folks would buy these prints from local merchants for slightly more than the cost of a bowl of noodles – about $5 to $10 US dollars today – and they would use these prints to decorate their homes. By comparison, a print of The Great Wave sold at auction for $1.11 million in September 2020.
These prints weren’t very large, either. The Great Wave measures 10 inches tall by 15 inches wide, and most prints were of similar size. That made them convenient to buy at the market, carry them home, and display on the wall. To understand how the Japanese people treated these prints in their day, think about the decorations in your homes that you bought at stores like Home Goods and Target. You probably have some screen prints or posters on your walls.
Since the target consumer for ukiyo-e prints were ordinary people with working-class budgets, they needed to be affordable, popular, and recognizable. When Hokusai published The Great Wave, it wasn’t a standalone piece. It was the first print in a series named Thirty-six Views of Mount Fuji. Below are three other prints from that series. The central feature in each print is Mount Fuji, which would be instantly recognizable to any Japanese person. The various views would also be relatable.



The features of these prints made them valuable. Anyone could find a favorite print or two out of a series of 36. They made art accessible. They were inexpensive yet impressive. They were artsy yet accessible. Artists like Hokusai knew what people wanted, and they delivered the goods.
This isn’t any different from software development. Features add value for the users. For example, if you’re developing a banking app, folks better be able to log in securely and view their latest transactions. If those features are broken or unintuitive, folks might as well move their accounts to other banks! We, as the developers and testers, are like the ukiyo-e artists: we need to know what our customers need. We need to make products that they not only want, but they also enjoy.
Features add value. However, I would use a better word to describe this aspect of a product: behavior. Behavior is the way one acts or conducts oneself. In software, we define behaviors in terms of inputs and responses. For example, login is a behavior: you enter valid credentials, and you expect to gain access. You gave inputs, the app did something, and you got the result.
My conviction on software testing AND development is that if you focus on good software behaviors, then everything else falls into place. When you plan development work, you prioritize the most important behaviors. When you test the features, you cover the most important behaviors. When users get your new product, they gain value from those features, and hopefully you make that money, just like Hokusai did.
This is why I strongly believe in the value of Behavior-Driven Development, or BDD for short. As a set of pragmatic practices, BDD helps you and your team stay focused on the things that matter. BDD involves activities like Three Amigos collaboration, Example Mapping, and writing Gherkin. When you focus on behavior – not on shiny new tech, or story points, or some other distractions – you win big.
Conviction #2: Prioritize on risk
Ukiyo-e artists depicted more than just views of Mount Fuji. In fact, landscape scenes became popular only during the late period of woodblock printing – the 1830s to the 1860s. Before then, artists focused primarily on people: geisha, courtesans, sumo wrestlers, kabuki actors, and legendary figures. These were all characters from the “floating world,” a world of pleasure and hedonism apart from the dreary everyday life of feudal Japan.
Here is a renowned print of a kabuki actor by Sharaku, printed in 1794:

Tōshūsai Sharaku, 1794
Sharaku was active only for one year, but he produced some of the most expressive portraits seen during ukiyo-e’s peak period. A yakko was a samurai’s henchman. In this portrait, we see Edobei ready for dirty deeds, with a stark grimace on his face and hands pulsing with anger.
Why would artists like Sharaku print faces like these? Because they would sell. Remember, ukiyo-e was not high-class art. It was a business. Artists would make a series of prints and sell them on the streets of Edo (now Tokyo). They needed to make prints that people wanted to buy. If they picked lousy or boring subjects, their prints wouldn’t sell. No soba noodles for them! So, what subjects did they choose? Celebrities. Actors. “Female beauties.” And some content that was not safe for work.
Artists prioritized their work based on business risk. They chose subjects that would be easy to sell. They pursued value. As testers, we should also prioritize test coverage based on risk.
I know there’s a popular slogan saying, “Test all the things!”, but that’s just impossible. It’s like saying, “Print all the pictures!” Modern apps are too complex to attempt any sort of “complete” or “100%” coverage. Instead, we should focus our testing efforts on the most important behaviors, the ones that would cause the most problems if they broke. Testing is ultimately a risk-mitigating activity. We do testing to de-risk problems that enter during development.
So, what does a risk-based testing strategy look like? Well, start by covering the most valuable behaviors. You can call them the MVBs. These are behaviors that are core to your app. If they break, then it’s game over. No soba noodles. For example, if you can’t log in, you’re done-zo. The MVBs should be tested before every release. They are non-negotiable test coverage. If your team doesn’t have enough resources to run these tests, then get more resources.
In addition to the MVBs, cover areas that were changed since the previous release. For example, if your banking app just added mobile deposits, then you should test mobile deposits. Things break where developers make changes. Also, look at testing different layers and aspects of the product. Not every test should be a web UI test. Add unit tests to pinpoint failures in the code. Add API tests to catch problems at the service layer. Consider aspects like security, accessibility, and visuals.
When planning these tests, try to keep them fast and atomic, covering individual behaviors instead of long workflows. Shorter tests are more reliable and give space for more coverage. And if you do have the resources for more coverage beyond the MVBs and areas of change, expand your coverage as resources permit. Keep adding coverage for the next most valuable behaviors until you either run out of time or the coverage isn’t worth the time.
Overall, ask yourself this when weighing risks: How painful would it be if a particular behavior failed? Would it ruin a user’s experience, or would they barely notice?
Conviction #3: Automate
The copy of The Great Wave shown at the top of this article is located at the Metropolitan Museum of Art in New York City. However, that’s not the only version. When ukiyo-e artists produced their prints, they kept printing copies until the woodblocks wore out! Remember, these weren’t precious paintings for the rich, they were posters for the commoners. One set of woodblocks could print thousands of impressions of popular designs for the masses. It’s estimated that there were five to eight thousand original impressions of The Great Wave, but nobody knows for sure. To this day, only a few hundred have survived. And much to my own frustration, museums that have copies do not put them on public display because the pieces are so fragile.
Here are different copies of The Great Wave from different museums:




Print production had to be efficient and smooth. Remember, this was a business. Publishers would make more money if they could print more impressions from the same set of woodblocks. They’d gain more renown if their prints maintained high quality throughout the lifetime of the blocks. And the faster they could get their prints to market, the sooner they could get paid and enjoy all the soba noodles.
What can we learn from this? Automate! That’s our third conviction.
What can we learn from this? Automate! Automation is a force multiplier. If Hokusai spent all his time manually laboring over one copy of The Great Wave, then we probably wouldn’t be talking about it today. But because woodblock printing was a whole process, he produced thousands of copies for everyone to enjoy. I wouldn’t call the woodblock printing process fully “automated” because it had several tedious steps with manual labor, but in Edo period Japan, it was about as automated as you could get.
Compare this to testing. If we run a test manually, we cover the target behavior one time. That’s it: lots of labor for one instance. However, if we automate that test, we can run it thousands of times. It can deliver value again and again. That’s the difference between a painting and a print.
So, how should we go about test automation? First, you should define your goals. What do you hope to achieve with automation? Do you want to speed up your testing cycles? Are you looking to widen your test coverage? Perhaps you want to empower Continuous Delivery through Continuous Testing? Carefully defining your goals from the start will help you make good decisions in your test automation strategy.
When you start automating tests, treat it like full software development. You aren’t just writing a bunch of scripts, you are developing a software system. Follow recommended practices. Use design patterns. Do code reviews. Fix bugs quickly. These principles apply whether you are using coded or codeless tools.
Another trap to avoid is delaying test automation. So many times, I’ve heard teams struggle to automate their tests because they schedule automation work as their lowest priority. They wish they could develop automation, but they just never have the time. Instead, they grind through testing their MVBs manually just to get the job done. My advice is flip that attitude right-side up. Automate first, not last. Instead of planning a few tests to automate if there’s time, plan to automate first and cover anything that couldn’t be automated with manual testing.
Furthermore, integrate automated tests into the team’s Continuous Integration system as soon as possible. Automated tests that aren’t running are dead to me. Get them running automatically in CI so they can deliver value. Running them nightly or even weekly can be a good start, as long as they run on a continuous cadence.
Finally, learn good practices. Test automation technologies are ever-evolving. It seems like new tools and frameworks hit the market all the time. If you’re new to automation or you want to catch up with the latest trends, then take time to learn. One of the best resources I can recommend is Test Automation University. TAU has about 70 courses on everything you can imagine, taught by the best instructors in the world, and it’s 100% FREE!
Now, you might be thinking, “Andy, come on, you know everything can’t be automated!” And that’s true. There are times when human intervention adds value. We see this in ukiyo-e prints, too. Here is Plum Garden at Kameido by Utagawa Hiroshige, Hokusai’s main rival. Notice the gradient colors of green and red in the background:

Utagawa Hiroshige, 1857
Printers added these gradients using a technique called bokashi, in which they would apply layers of ink to the woodblocks by hand. Sometimes, they would even paint layers directly on the prints. In these cases, the “automation” of the printing process was insufficient, and humans needed to manually intervene.
It’s always good to have humans test-drive software. Automation is great for functional verification, but it can’t validate user experience. Exploratory testing is an awesome complement to automated testing because it mitigates different risks.
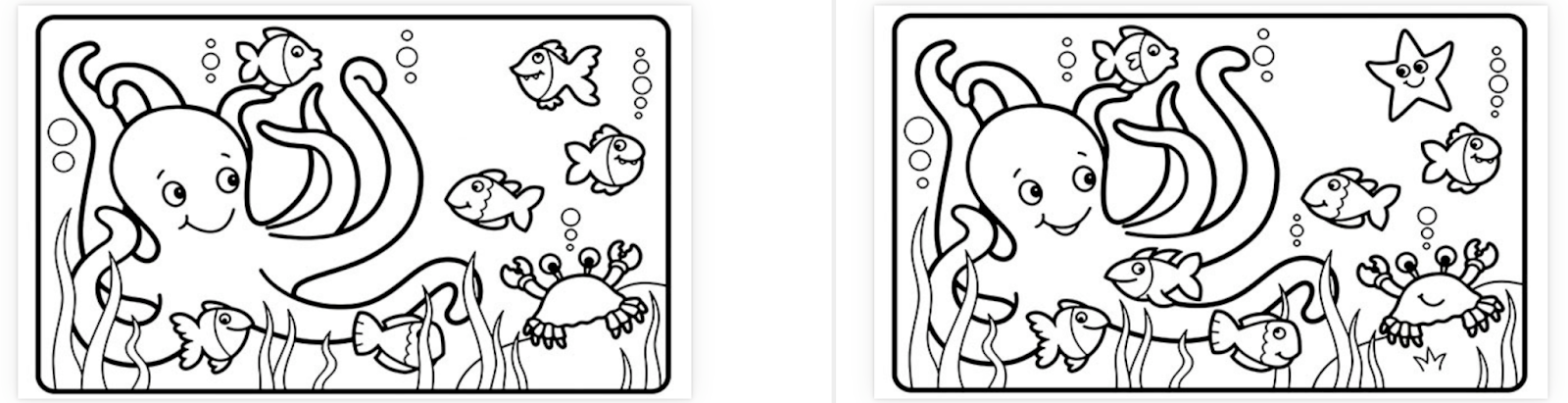
Nevertheless, automation is able to do things it could never do before. As I said before, I work at Applitools, where we specialize in automated visual testing. Take a look at these two prints of Matsumoto Hoji’s Frog from Meika Gafu. Notice anything different between the two?

If we use Visual AI to compare these two prints, it will quickly identify the main difference:

The signature block is in a different location! Small differences like small pixel offsets are ignored, while major differences are highlighted. If you apply this style of visual testing to your web and mobile apps, you could catch a ton of visual bugs before they cause problems for your users. Modern test automation can do some really cool tricks!
Conviction #4: Shift left and right
Mokuhanga, or woodblock printing, was a huge process with multiple steps. Artists like Hokusai and Hiroshige did not print their artwork themselves. In fact, printing required multiple roles to be successful: a publisher, an artist, a carver, and a printer.
- The publisher essentially ran the process. They commissioned, financed, and distributed prints. They would even collaborate with artists on print design to keep them up with the latest trends.
- The artist designed the patterns for the prints. They would sketch the patterns on washi paper and give instructions to the carver and printer on how to properly produce the prints.
- The carver would chisel the artist’s pattern into a set of wooden printing blocks. Each layer of ink would have its own block. Carvers typically used a smooth, hard wood like cherry.
- The printer used the artist’s patterns and carver’s woodblocks to actually make the prints. They would coat the blocks in appropriately-colored water-based inks and then press paper onto the blocks.
Quality had to be considered at every step in the process, not just at the end. If the artist was not clear about colors, then the printer might make a mistake. If the carver cut a groove too deep, then ink might not adhere to the paper as intended. If the printer misaligned a page during printing, then they’d need to throw it away – wasting time, supplies, and woodblock life – or risk tarnishing everyone’s reputation with a misprint. Hokusai was noted for his stringent quality standards for carvers and printers.
The words of W. Edwards Deming ring true:
Inspection does not improve the quality, nor guarantee quality. Inspection is too late. The quality, good or bad, is already in the product. As Harold F. Dodge said, “You cannot inspect quality into a product.”
W. Edwards deming
This is just like software development. We can substitute the word “testing” for “inspection” in Deming’s quote. Testers don’t exclusively “own” quality. Every role – business, development, and testing – has a responsibility for high-caliber work. If a product owner doesn’t understand what the customer needs, or a developer skips code reviews, or if a tester neglects an important feature, then software quality will suffer.
How do we engage the whole team in quality work? Shift left and right.
Most testers are probably familiar with the term shift left. It means, start doing testing work earlier in the development process. Don’t wait until developers are “done” and throw their code “over the fence” to be tested. Run tests continuously during development. Automate tests in-sprint. Adopt test-driven and behavior-driven practices. Require unit tests. Add test implementation to the “Definition of Done.”
But what about shift right? This is a newer phase, but not necessarily a newer practice. Shift right means, continue to monitor software quality during and after releases. Build observability into apps. Monitor apps for bugs, failures, and poor performance. Do canary deployments to see how systems respond to updates. Perform chaos testing to see how resilient environments are to outages. Issue different UIs to user groups as part of A/B testing to find out what’s most effective. And feed everything you learn back into development a la “shift left.”

(Source: https://www.atlassian.com/devops)
The famous DevOps infinity loop shows how “shift left” and “shift right” are really all part of the same flow. If you start in the middle where the paths cross, you can see arrows pointing leftward for feedback, planning, and building. Then, they push rightward with continuous integration, deployment, monitoring, and operations. We can (and should) take all the quality measures we said before as we spin through this loop perpetually. When we plan, we should build quality in with good design and feedback from the field. When we develop, we should do testing together with coding. As we deploy, automated safety checks should give thumbs-up or thumbs-down. Post-deployment, we continue to watch, learn, and adjust.
Conviction #5: Give fast feedback
The acronym CI/CD is ubiquitous in our industry, but I feel like it’s missing something important: “CT”, or Continuous Testing. CI and CD are great for pushing code fast, but without testing, they could be pushing garbage. Testing does not improve quality directly, but continuous revelation of quality helps teams find and resolve issues fast. It demands response. Continuous Testing keeps the DevOps infinity loop safe.
Fast feedback is critical. The sooner and faster teams discover problems, the less pain those problems will cause. Think about it: if a developer is notified that their code change caused a failure within a minute, they can immediately flip back to their code, which is probably still open in an editor. If they find out within an hour, they’ll still have their code fresh in their mind. Within a day, it’ll still be familiar. A week or more later? Fuggedaboutit! Heaven forbid the problem goes undetected until a customer hits it.
Continuous testing enables fast feedback. Automation enables continuous testing. Test automation that isn’t running continuously is worthless because it provides no feedback.
Japanese woodblock printers also relied on fast feedback. If they noticed anything wrong with the prints as they pressed them, they could scrap the misprint and move on. However, since they were meticulous about quality, misprints were rare. Nevertheless, each print was unique because each impression was done manually. The amount, placement, and hue of ink could vary slightly from print to print. Over time, the woodblocks themselves wore down, too.
Here, you can see differences in the title cartouche between different prints of The Great Wave:

(Source: https://blog.britishmuseum.org/the-great-wave-spot-the-difference/)
On the left, the outline around the title is solid, whereas on the right, the outline has breaks. This is because the keyblock had very fine ridges for printing outlines, which suffered the most from wear and tear during repeated impressions. Furthermore, if you look very closely, you can see that the Japanese characters appear bolder on the right than the left. The printer must have used more ink or pressed the title harder for the impression on the right.
Printers would need to spot these issues quickly so they could either correct their action for future prints or warn the publisher that the woodblocks were wearing down. If the print was popular, the publisher could commission a carver to carve new woodblocks to keep production going.
Conviction #6: Go lean
As I’ve said many times now, woodblock printing was a business. Ukiyo-e was commercial art, and competition was fierce. By the 1840s, production peaked with about 250 different publishers. Artists like Hokusai and Hiroshige were rivals. While today we recognize famous prints like The Great Wave, countless other prints were also made.
Publishers competed in a rat race for the best talent and the best prints. They had to be savvy. They had to build good reputations. They needed to respond to market demands for subject material. For example, Kitagawa Utamaro was famous for prints of “female beauties.”

Kitagawa Utamaro, 1795
Ukiyo-e artists also took inspiration from each other. If one artist made a popular design, then other artists would copy their style. Here is a print from Hiroshige’s series, Thirty-Six Views of Mount Fuji. That’s right, Hokusai’s biggest rival made his own series of 36 prints about Mount Fuji, and he also made his own version of The Great Wave. If you can’t beat ‘em, join ‘em!

Utagawa Hiroshige, 1858
Publishers also had to innovate. Oftentimes, after a print had been in production for a while, they would instruct the printer to change the color scheme. Here are two versions of Hokusai’s Kajikazawa in Kai Province, from Thirty-six Views of Mount Fuji:

The print on the left is an early impression. The only colors used were shades of blue. This was Hokusai’s original artistic intention. However, later prints, like the one on the right, added different colors to the palette. The fishermen now wear red coats. The land has a bokashi green-yellow gradient. The sky incorporates orange tones to contrast the blue. Publishers changed up the colors to squeeze more money out of existing designs without needing to pay artists for new work or carvers for new woodblocks.
However, sometimes when doing this, artistic quality was lost. Compare the fine detail in the land between these two prints. In the early impression, you can see dark blue shading used to pronounce the shadows on the side of the rocks, giving them height and depth, and making the fisherman appear high above the water. However, in the later impression, the green strip of land has almost no shading, making it appear flat and less prominent.
Ukiyo-e publishers would have completely agreed with today’s lean business model. Seek first and foremost to deliver value to your customers. Learn what they want. Try some designs, and if they fail, pivot to something else. When you find what works, get a full end-to-end process in place, and then continuously improve as you go. Respond quickly to changes.
Going lean is very important for software testing, too. Testing is engineering, and it has serious business value. At the same time, testing activities never seem to have as many resources as they should. Testers must be scrappy to deliver valuable quality feedback using the resources they have.
When I think about software testing going lean, I’m not implying that testers should skip tests or skimp on coverage. Rather, I’m saying that world-class systems and processes cannot be built overnight. The most important thing a team can do is build basic end-to-end feedback loops from the start, especially for test automation.

So many times, I’ve seen teams skew their test automation strategy entirely towards implementation. They spend weeks and weeks developing suites of automated tests before they set up any form of Continuous Testing. Instead of triggering tests as part of Continuous Integration, folks must manually push buttons or run commands to make them start. Other folks on the team see results sporadically, if ever. When testers open bug reports, developers might feel surprised.
I recommend teams set up Continuous Testing with feedback loops from the start. As soon as you automate your first test, move onto running it from CI and sending you notifications for results before automating your second test. Close the feedback loop. Start delivering results immediately. As you find hotspots, add more coverage. Talk with developers about the kinds of results they find most valuable. Then, grow your suite once you demonstrate its value. Increase the throughput. Turn those sidewalks into highways. Continue to iteratively improve upon the system as you go. Don’t waste time on tests that don’t matter or dashboards that nobody reads. Going lean means allocating your resources to the most valuable activities. What you’ll find is that success will snowball!
Conviction #7: Open up
Once you have a good thing going, whether it’s woodblock printing or software testing, how can you take it to the next level? Open up! Innovation stalls when you end up staring at your own belly button for too long. Outside influences inspire new creativity.
Ukiyo-e prints had a profound impact on Western art. After Japan opened up to the rest of the world in the mid-1800s, Europeans became fascinated by Japanese art, and European artists began incorporating Japanese styles and subjects into their work. This phenomenon became known as Japonisme. Here, Claude Monet, famous for his impressionist paintings, painted a picture of his wife wearing a kimono with fans adorning the wall behind her:

Claude Monet, 1876
Vincent van Gogh in particular loved Japanese woodblock prints. He painted his own versions of different prints. Here, we see Hiroshige’s Plum Garden at Kameido side-by-side with Van Gogh’s Flowering Plum Orchard (after Hiroshige):


Van Gogh was drawn to the bold lines and vibrant colors of ukiyo-e prints. There is even speculation that The Great Wave inspired the design of The Starry Night, arguably Van Gogh’s most famous painting:


Notice how the shapes of the waves mirror the shapes of the swirls in the sky. Notice also how deep shades of blue contrast yellows in each. Ukiyo-e prints served as great inspiration for what became known as Modern art in the West.
Influence was also bidirectional. Not only did Japan influence the West, but the West influenced Japan! One thing common to all of the prints in Thirty-six Views of Mount Fuji is the extensive use of blue ink. Prussian blue pigment had recently come to Japan from Europe, and Hokusai’s publisher wanted to make extensive use of the new color to make the prints stand out. Indeed, they did. To this day, Hokusai is renowned for popularizing the deep shades of Prussian blue in ukiyo-e prints.
It’s important in any line of work to be open to new ideas. If Hokusai had not been willing to experiment with new pigments, then we wouldn’t have pieces like The Great Wave.
That’s why I’m a huge proponent of Open Testing. What if we open our tests like we open our source? There are so many great advantages to open source software: helping folks learn, helping folks develop better software, and helping folks become better maintainers. If we become more open in our testing, we can improve the quality of our testing work, and thus also the quality of the software products we are building. Open testing involves many things: building open source test frameworks, getting developers involved in testing, and even publicly sharing test cases and results.
Conviction #8: Show empathy
In this article, we’ve seen lots of great artwork, and we’ve learned lots of valuable lessons from it. I think ukiyo-e prints remain popular today because their subject matter focuses on the beauty of the world. Artists strived to make pieces of the “floating world” tangible for the common people.
Ukiyo-e prints revealed the supple humanity of the Japanese people, like in this print by Utagawa Kunisada:

Utagawa Kunisada, 1850
They revealed the serene beauty of nature in harmony with civilization, like in these prints from Hiroshige’s One Hundred Famous Views of Edo:

Utagawa Hiroshige, 1856-1858
Ukiyo-e prints also revealed ordinary people living out their lives, like this print from Hokusai’s Thirty-six Views of Mount Fuji:

Katsushika Hokusai, 1830
Art is compelling. And software, like art, is meant for people. Show empathy. Care about your customers. Remember, as a tester, you are advocating for your users. Try to help solve their problems. Do things that matter for them. Build things that actually bring them value. Be thoughtful, mindful, and humble. Don’t be a jerk.
The Golden Conviction
These eight convictions are things I’ve learned the hard way throughout my career:
- Focus on behavior
- Prioritize on risk
- Automate
- Shift left and right
- Give fast feedback
- Go lean
- Open up
- Show empathy
I live and breathe these convictions every day. Whether you are making woodblock prints or running test cases, these principles can help you do your best work.
If I could sum up these eight convictions in one line, it would be this: Be excellent in all things. If you test software, then you are both an artist and an engineer. You have a craft. Do it with excellence.






































{kind=link}