Django is a fantastic Python Web framework, and one of its great out-of-the-box features is internationalization (or “i18n” for short). It’s pretty easy to add translations to nearly any string in a Django app, but what about translating admin site pages? Titles, names, and actions all need translations. Those admin pages are automatically generated, so how can their words be translated? This guide shows you how to do it easily.
i18n Review
If you are new to translations in Django, definitely read the official Translation page first. In a nutshell, all strings that need translation should be passed into a translation function for Python code or a translation block for Django template code. Django management commands then generate language-specific message files, in which translators provide translations for the marked strings, and finally compile them for app use. Note that translations require the gettext tools to be installed on your machine. Django also provides some advanced logic for handling special cases like date formats and pluralization, too. It’s really that simple!
Initial Setup
A Django project needs some basic config before doing translations, which is needed for both the main site and the admin.
Enabling Internationalization
Make sure the following settings are given in settings.py:
# settings.py
LANGUAGE_CODE = 'en-us' # or other appropriate code
USE_I18N = True
USE_L10N = True
They were probably added by default. The Booleans could be set to False to give apps with no internationalization a small performance boost, but we need them to be True so that translations happen.
Changing Locale Paths
By default, message files will be generated into locale directories for each app with strings marked for translation. You may optionally want to set LOCALE_PATHS to change the paths. For example, it may be easiest to put all message files into one directory like this, rather than splitting them out by app:
# settings.py
LOCALE_PATHS = [os.path.join(BASE_DIR, 'locale')]
This will avoid translation duplication between apps. It’s a good strategy for small projects, but be warned that it won’t scale well for larger projects.
Middleware for Automatic Translation
Django provides LocaleMiddleware to automatically translate pages using “context clues” like URL language prefixes, session values, and cookies. (The full pecking order is documented under How Django discovers language preference on the official doc page.) So, if a user accesses the site from China, then they should automatically receive Chinese translations! To use the middleware, add django.middleware.locale.LocaleMiddleware to the MIDDLEWARE setting in settings.py. Make sure it comes after SessionMiddleware and CacheMiddleware and before CommonMiddleware, if those other middlewares are used.
# settings.py
MIDDLEWARE = [
# ...
'django.middleware.locale.LocaleMiddleware',
# ...
]
URL Pattern Language Prefixes
Getting automatic translations from context clues is great, but it’s nevertheless useful to have direct URLs to different page translations. The i18n_patterns function can easily add the language code as a prefix to URL patterns. It can be applied to all URLs for the site or only a subset of URLs (such as the admin site). Optionally, patterns can be set so that URLs without a language prefix will use the default language. The main caveat for using i18n_patterns is that it must be used from the root URLconf and not from included ones. The project’s root urls.py file should look like this:
# urls.py
from django.conf.urls.i18n import i18n_patterns
from django.contrib import admin
from django.urls import path
urlpatterns = i18n_patterns(
# ...
path('admin/', admin.site.urls),
# ...
# If no prefix is given, use the default language
prefix_default_language=False
)
Limiting Language Choices
When adding language prefixes to URLs, I strongly recommend limiting the available languages. Django includes ready-made message files for several languages. A site would look bad if, for example, the “/fr/” prefix were available without any French translations. Set the available languages using LANGUAGES in settings.py:
# settings.py
from django.utils.translation import gettext_lazy as _
LANGUAGES = [
('en', _('English')),
('zh-hans', _('Simplified Chinese')),
]
Note that language codes follow the ISO 639-1 standard.
Doing the Translations
With the configurations above, translations can now be added for the main site! The steps below show how to add translations specifically for the admin. Unless there is a specific need, use lazy translation for all cases.
Out-of-the-Box Phrases
Admin site pages are automatically generated using out-of-the-box templates with lots of canned phrases for things like “login,” “save,” and “delete.” How do those get translated? Thankfully, Django already has translations for many major languages. Check out the list under django/contrib/admin/locale for available languages. Django will automatically use translations for these languages in the admin site – there’s nothing else you need to do! If you need a language that’s not available, I strongly encourage you to contribute new translations to the Django project so that everyone can share them. (I suspect that you could also try to manually create messages files in your locale directory, but I have not tested that myself.)
Custom Admin Titles
There are a few ways to set custom admin site titles. My preferred method is to set them in the root urls.py file. Wherever they are set, mark them for lazy translation. It’s easy to overlook them!
from django.contrib import admin
from django.utils.translation import gettext_lazy as _
admin.site.index_title = _('My Index Title')
admin.site.site_header = _('My Site Administration')
admin.site.site_title = _('My Site Management')
App Names
App names are another set of phrases that can be easily missed. Add a verbose_name field with a translatable string to every AppConfig class in the project. Do not simply try to translate the string given for the name field: Django will yield a runtime exception!
from django.apps import AppConfig
from django.utils.translation import gettext_lazy as _
class CustomersConfig(AppConfig):
name = 'customers'
verbose_name = _('Customers')
Model Names
Models are full of strings that need translations. Here are the things to look for:
- Give each field a verbose_name value, since the identifiers cannot be translated.
- Mark help texts, choice descriptions, and validator messages as translatable.
- Add a Meta class with verbose_name and verbose_name_plural values.
- Look out for any other strings that might need translations.
Here is an example model:
from django.db import models
from django.core.validators import RegexValidator
from django.utils.translation import gettext_lazy as _
class Customer(models.Model):
name = models.CharField(
max_length=100,
help_text=_('First and last name.'),
verbose_name=_('name'))
address = models.CharField(
max_length=100,
verbose_name=_('address'))
phone = models.CharField(
max_length=10,
validators=[RegexValidator(
'^\d{10}$',
_('Phone must be exactly 10 digits.'))],
verbose_name=_('phone number'))
class Meta:
verbose_name = _('customer')
verbose_name_plural = _('customers')
Run the Commands
Once all strings are marked for translation, generate the message files:
# Generate message files for a desired language
python manage.py makemessages -l zh_Hans
# After adding translations to the .po files, compile the messages
python manage.py compilemessages
Warning: The language code and the locale name may be different! For example, take Simplified Chinese: the language code is “zh-hans”, but the locale name is “zh_Hans”. Notice the underscore and the caps. Locale names often include a country code to differentiate language nuances, like American English vs. British English. Refer to django/contrib/admin/local for a list of examples.
Bonus: Admin Language Buttons
With LocaleMiddleware and i18n_patterns, pages should be automatically translated based on context or URL prefix. However, it would still be great to let the user manually switch the language from the admin interface. Clicking a button is more intuitive than fumbling with URL prefixes.
There are many ways to add language switchers to the admin site. To me, the most sensible way is to add flag icons to the title bar. Behind the scenes, each flag icon would be linked to a language-prefixed URL for the page. That way, whenever a user clicks the flag, then the same page is loaded in the desired language.

Language Code Prefix Switcher
Since URL paths use i18n_patterns, their language codes can be trusted to be uniform. A utility function can easily add or substitute the desired language code as a URL path prefix. For example, it would convert “/admin/” and “/en/admin/” into “/zh-hans/admin/” for Simplified Chinese. This function should also validate that the path and language are correct. It can be put anywhere in the project. Below is the code:
from django.conf import settings
def switch_lang_code(path, language):
# Get the supported language codes
lang_codes = [c for (c, name) in settings.LANGUAGES]
# Validate the inputs
if path == '':
raise Exception('URL path for language switch is empty')
elif path[0] != '/':
raise Exception('URL path for language switch does not start with "/"')
elif language not in lang_codes:
raise Exception('%s is not a supported language code' % language)
# Split the parts of the path
parts = path.split('/')
# Add or substitute the new language prefix
if parts[1] in lang_codes:
parts[1] = language
else:
parts[0] = "/" + language
# Return the full new path
return '/'.join(parts)
Prefix Switch Template Filter
Ultimately, this function must be called by Django templates in order to provide links to language-specific pages. Thus, we need a custom template filter. The filter implementation module can be put into any app, but it must be in a sub-package named templatetags – that’s how Django knows to look for custom template tags and filters. The new filters will be easy to write because we already have the switch_lang_code function. (Separating the logic to handle the prefix from the filter itself makes both more testable and reusable.) The code is below:
# [app]/templatetags/i18n_switcher.py
from django import template
from django.template.defaultfilters import stringfilter
register = template.Library()
@register.filter
@stringfilter
def switch_i18n_prefix(path, language):
"""takes in a string path"""
return switch_lang_code(path, language)
@register.filter
def switch_i18n(request, language):
"""takes in a request object and gets the path from it"""
return switch_lang_code(request.get_full_path(), language)
Admin Template Override
Finally, admin templates must be overridden so that we can add new elements to the admin pages. Any admin template can be overridden by creating new templates of the same name under [project-root]/templates/admin. Parent content will be used unless explicitly overridden within the child template file. Since we want to change the title bar, create a new template file for base_site.html with the following contents:
{% extends "admin/base_site.html" %}
{% load static %}
{% load i18n %}
<!-- custom filter module -->
{% load i18n_switcher %}
{% block extrahead %}
<link rel="shortcut icon" href="{% static 'images/favicon.ico' %}" />
<link rel="stylesheet" type="text/css" href="{% static 'css/custom_admin.css' %}"/>
{% endblock %}
{% block userlinks %}
<a href="{{ request|switch_i18n:'en' }}">
<img class="i18n_flag" src="{% static 'images/flag-usa-16.png' %}"/>
</a> /
<a href="{{ request|switch_i18n:'zh-hans' }}">
<img class="i18n_flag" src="{% static 'images/flag-china-16.png' %}"/>
</a> /
{% if user.is_active and user.is_staff %}
{% url 'django-admindocs-docroot' as docsroot %}
{% if docsroot %}
<a href="{{ docsroot }}">{% trans 'Documentation' %}</a> /
{% endif %}
{% endif %}
{% if user.has_usable_password %}
<a href="{% url 'admin:password_change' %}">{% trans 'Change password' %}</a> /
{% endif %}
<a href="{% url 'admin:logout' %}">{% trans 'Log out' %}</a>
{% endblock %}
The static CSS file named css/custom_admin.css should have the following contents:
.i18n_flag img {
width: 16px;
vertical-align: text-top;
}
Notice that the whole userlinks block had to be rewritten to fit the flag into place. The static image files for the flags are simply free flag emojis. They are hyperlinked to the appropriate language URL for the page: the switch_i18n filter is applied to the active request object to get the desired language-prefixed path. (Note: In my example code, I removed the “View Site” link because my site didn’t need it.)
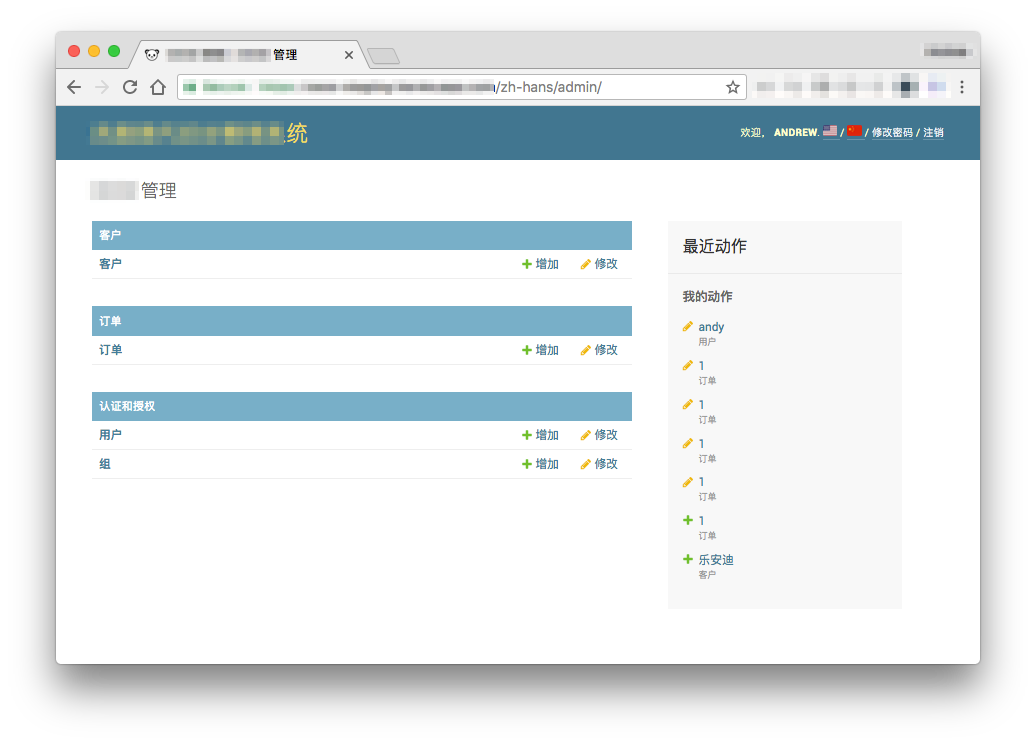
Completed View
The admin site should now look like this:


In my project, I chose to put the language prefix switcher code in its own application named i18n_switcher. The files in my project needed for the admin language buttons are organized like this (without showing other files in the project):
[root]
|- i18n_switcher
| |- templatetags
| | |- __init__.py
| | `- i18n_switcher.py
| |- __init__.py
| `- apps.py
|- locale
| `- zh_Hans
| `- LC_MESSAGES
| |- django.mo
| `- django.po
|- static
| |- css
| | `- custom_admin.css
| `- images
| |- flag-china-16.png
| `- flag-usa-16.png
`- templates
`- admin
`- base_site.htmlSince I created a new app for the new code, I also had to add the app name to INSTALLED_APPS in settings.py:
# settings.py
INSTALLED_APPS = [
# ...
'i18n_switcher.apps.I18NSwitcherConfig',
# ...
]
As mentioned before, flag icons in the title bar are simply one way to provide easy links to translated pages. It works well when there are only a few language choices available. A different view would be better for more languages, like a dropdown, a second line in the title bar, or even a page footer.
With a bit more polishing, this would also make a nifty little Django app package that others could use for their projects. Maybe I’ll get to that someday.



























