My original GitHub username is “AndyLPK247“. I created it long before I became the “Automation Panda.” However, I’d like my GitHub account to match the name of my blog (AutomationPanda.com) and my Twitter handle (@AutomationPanda). Using the same name across platforms makes it easier for folks to recognize my work. Plus, I’m writing a book, and I want the links printed in the book to reference Automation Panda.
Therefore, I created a new GitHub account named “AutomationPanda“. (Actually, I created it a while ago to reserve it, just in case I ever wanted to make a change.) I decided to create an entirely new account instead of simply changing my existing account’s username because I’ve created many materials – articles, videos, and courses – that link to my “AndyLPK247” account. If I were to change that username, then many of those links would break. (GitHub’s docs state that repository links would redirect to the new username, but links to gists and to the old name itself would break.)
From this moment forward, I will use “AutomationPanda” as my primary GitHub account. I intend to create all my new repositories under “AutomationPanda” while preserving existing repositories under “AndyLPK247”. Maintaining two GitHub accounts will be a bit of a hassle, but I think it is the best strategy for my situation. Over time, the new account will supersede the old.
SpecFlow is an excellent Behavior-Driven Development test framework for .NET. Recently, SpecFlow released a new reporting tool called SpecFlow+ LivingDoc, which generates living documentation for features. It combines all scenarios from all SpecFlow feature files into one central HTML report. The report looks crisp and professional. It is filterable and can optionally show test results. Teams can generate updated reports as part of their Continuous Integration pipelines. The best part is that SpecFlow+ LivingDoc, along with all other features, is completely free to use – all you need to do is register for a free SpecFlow account. There is no reason for any SpecFlow project to not also use LivingDoc.
SpecFlow provides rich documentation on all of SpecFlow+ LivingDoc’s benefits, features, and configurations. In this article, I won’t simply repeat what the official docs already state. Instead, I’m going to share how my team and I at PrecisionLender, a Q2 Company, adopted SpecFlow+ LivingDoc into our test automation solution. I’ll start by giving a brief overview of how we test the PrecisionLender web app. Then, I’ll share why we wanted to make LivingDoc part of our quality workflow. Next, I’ll walk through how we added the new report to our testing pipelines. Finally, as an advanced technique, I’ll show how we modified some of the LivingDoc data files to customize our reports. My goal for this article is to demonstrate the value SpecFlow+ LivingDoc adds to BDD collaboration and automation practices.
PrecisionLender’s Test Automation
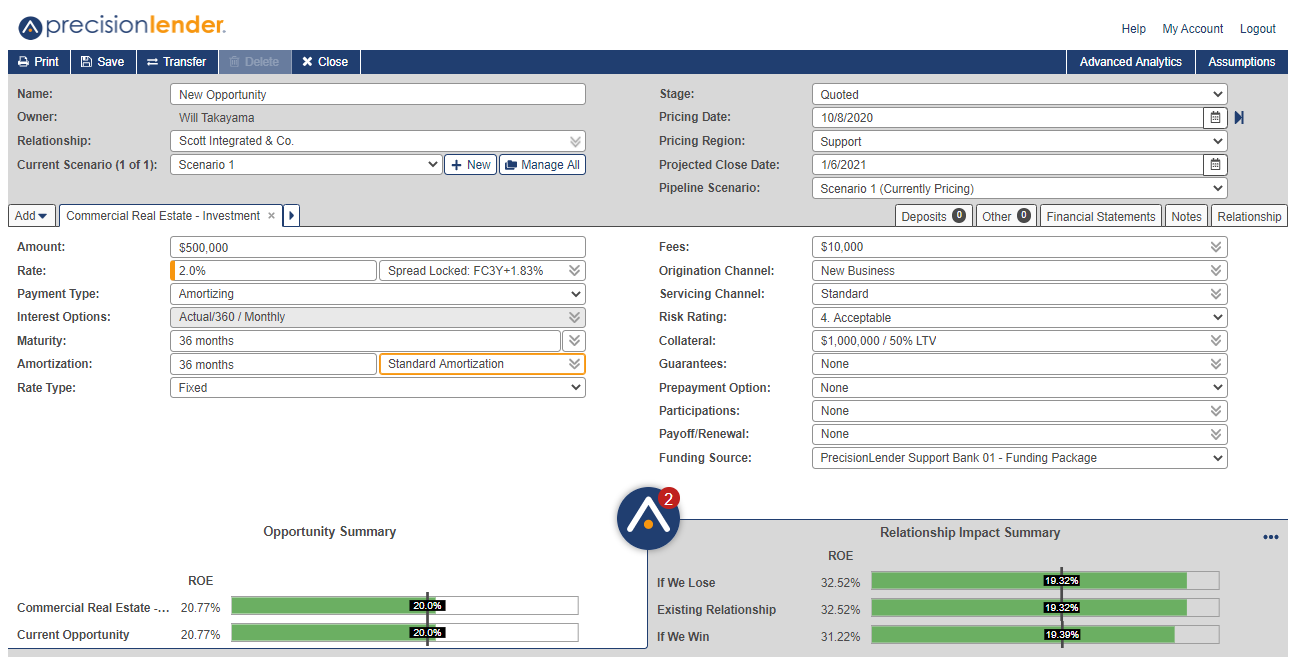
PrecisionLender is a web application that empowers commercial bankers with in-the-moment insights that help them structure and price commercial deals. Andi®, PrecisionLender’s intelligent virtual analyst, delivers these hyper-focused recommendations in real time allowing relationship managers to make data-driven decisions while pricing their commercial deals.
The PrecisionLender app is quite complex. It has several rich features to help bankers price any possible nuance for loan opportunities. Some banks also have unique configurations and additional features that make testing challenging.
On top of thorough unit testing, we run suites of end-to-end tests against the PrecisionLender web app. Our test automation solution is named “Boa,” and it is written in C# using SpecFlow for test cases and Boa Constrictor for Web UI and REST API interactions. We use BDD practices like Three Amigos, Example Mapping, and Good Gherkin to develop behaviors and cover them with automated tests. As of January 2021, Boa has over 1400 unique tests that target multiple test bank configurations. We run Boa tests continuously (for every code change), nightly (across all test banks), and “release-ly” (every two weeks before production deployments) at a rate of ~15K test iterations per week. Each test takes roughly half a minute to complete, and we run tests in parallel with up to 32 threads using Selenium Grid.
Introducing SpecFlow+ LivingDoc
SpecFlow+ LivingDoc is living documentation for features. SpecFlow started developing the tool a few years ago, but in recent months under Tricentis, they have significantly ramped up its development with the standalone generator and numerous feature enhancements. To learn about LivingDoc, watch this short introduction video:
When I saw the new SpecFlow+ LivingDoc reports, I couldn’t wait to try them myself. I love SpecFlow, and I’ve used it daily for the past few years. I knew it would bring value to my team at PrecisionLender.
Why Adopt SpecFlow+ LivingDoc?
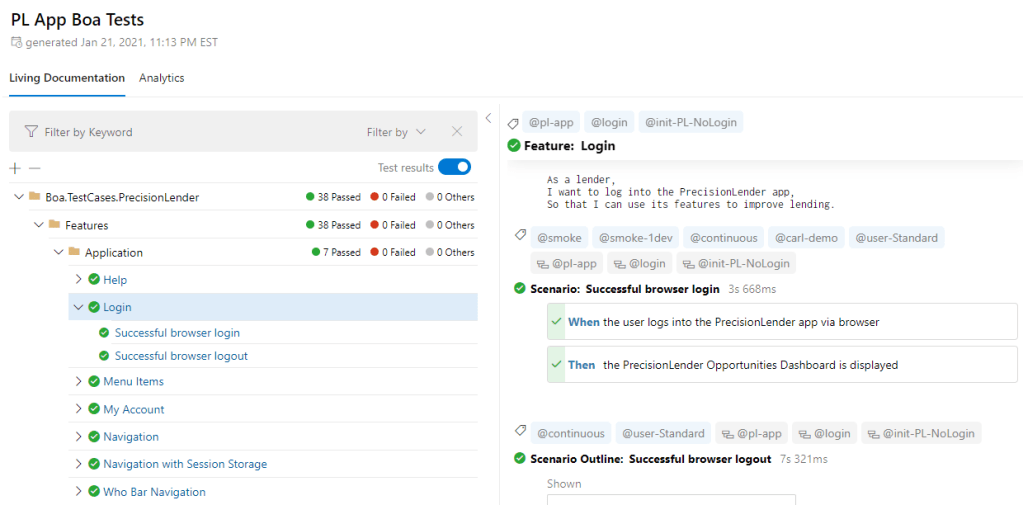
My team and I wanted to bring SpecFlow+ LivingDoc into our testing workflow for a few reasons. First and foremost, we wanted to share our features with every team member, whether they were in business, development, or testing roles. I originally chose SpecFlow to be the core test framework for our Boa tests because I wanted to write all tests in plain-language Gherkin. That way, product owners and managers could read and understand our tests. We could foster better discussions about product behaviors, test coverage, and story planning. However, even though tests could be understood by anyone, we didn’t have an effective way to share them. Feature files for tests must be stored together with automation code in a repository. Folks must use Visual Studio or a version control tool like Git to view them. That’s fine for developers, but it’s inaccessible for folks who don’t code. SpecFlow+ LivingDoc breaks down that barrier. It combines all scenarios from all feature files into one consolidated HTML report. Folks could use a search bar to find the tests they need instead of plunging through directories of feature files. The report could be generated by Continuous Integration pipelines, published to a shared dashboard, or emailed directly to stakeholders. Pipelines could also update LivingDoc reports any time features change. SpecFlow+ LivingDoc would enable us to actually share our features instead of merely saying that we could.
SpecFlow+ LivingDoc Living Documentation for PrecisionLender Features
Second, we liked the concise test reporting that SpecFlow+ LivingDoc offered. The SpecFlow+ Runner report, which our team already used, provides comprehensive information about test execution: full log messages, duration times, and a complete breakdown of pass-or-fail results by feature and scenario. That information is incredibly helpful when determining why tests fail, but it is too much information when reporting failures to managers. LivingDoc provides just the right amount of information for reporting high-level status: the tests, the results per test, and the pass-or-fail totals. Folks can see test status at a glance. The visuals look nice, too.
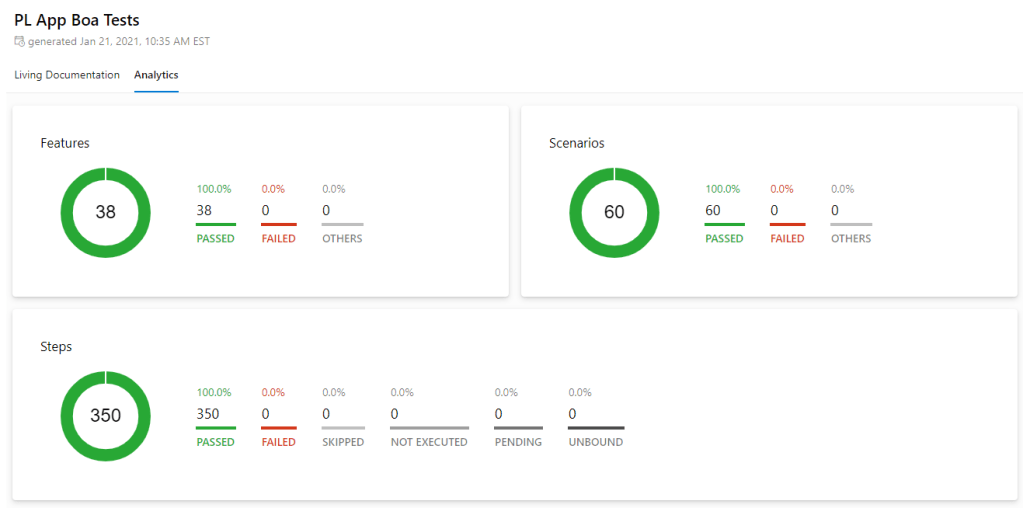
SpecFlow+ LivingDoc Analytics for PL App Boa Tests
Third, we wanted to discover any unused step definitions in our C# automation code. The Boa test solution is a very large automation project. As of January 2020, it has over 1400 unique tests and over 1100 unique step definitions, and those numbers will increase as we continue to add new tests. Maintaining any project of this size is a challenge. Sometimes, when making changes to scenarios, old step definitions may no longer be needed, but testers may not think to remove them from the code. These unused step definitions then become “dead code” that bloats the repository. It’s easy to lose track of them. SpecFlow+ LivingDoc offers a special option to report unused step definitions on the Analytics tab. That way, the report can catch dead steps whenever they appear. When I generated the LivingDoc report for the Boa tests, I discovered over a hundred unused steps!
SpecFlow+ LivingDoc Unused Step Definitions
Fourth and finally, my team and I needed a test report that we could share with customers. At PrecisionLender, our customers are banks – and banks are very averse to risk. Some of our customers ask for our test reports so they can take confidence in the quality of our web app. When sharing any information with customers, we need to be careful about what we do share and what we don’t share. Internally, our Boa tests target multiple different system configurations, and we limit the test results we share with customers to the tests for the features they use. For example, if a bank doesn’t factor deposits into their pricing calculations, then that bank’s test report should not include any tests for deposits. The reports should also be high-level instead of granular: we want to share the tests, their scenarios, and their pass-or-fail results, but nothing more. SpecFlow+ LivingDoc fits this need perfectly. It provides Gherkin scenarios with their steps in a filterable tree, and it visually shows results for each test as well as in total. With just a little bit of data modification (as shown later in this article), the report can include exactly the intended scenarios. Our team could use LivingDoc instead of generating our own custom report for customers. LivingDoc would look better than any report we would try to make, too!
Setting Up SpecFlow+ LivingDoc
At PrecisionLender, we currently use JetBrains TeamCity to schedule and launch Boa tests. Some tests launch immediately after app deployments, while others are triggered based on the time of day. When a test pipeline is launched, it follows these steps:
Check out the code repository.
Build the Boa test automation solution.
For each applicable bank configuration, run appropriate Boa tests.
We wanted to add SpecFlow+ LivingDoc in two places: after the build completes and after tests run for each configuration. The LivingDoc generated for the build step would not include test results. It would show all scenarios in all features, and it would also include the unused step definitions. This report would be useful for showing folks our tests and our coverage. The LivingDoc generated for each test run, however, would include test results. Since we run tests against multiple configurations, each run would need its own LivingDoc report. Not all tests run on each configuration, too. Generating LivingDoc reports at each pipeline step serve different needs.
Adding SpecFlow+ LivingDoc to our testing pipelines required only a few things to set up. The first step was to add the SpecFlow.Plus.LivingDocPlugin NuGet package to the .NET test project. Adding this NuGet package makes SpecFlow automatically save test results to a file named TestExecution.json every time tests run. The docs say you can customize this output path using specflow.json, too.
Required SpecFlow NuGet packages, including SpecFlow.Plus.LivingDocAn example snippet of TestExecution.json
The next step was to install the LivingDoc CLI tool on our TeamCity agents. The CLI tool is a dotnet command line tool, so you need the .NET Core SDK 3.1 or higher. Also, note that you cannot install this package as a NuGet dependency for your .NET test project. (I tried to do that in the hopes of simplifying my build configuration, but NuGet blocks it.) You must install it to your machine’s command line. The installation command looks like this:
All the “$” variables are paths configured in our TeamCity projects. I chose to generate reports using the test assembly because I discovered that results wouldn’t appear in the report if I generated them from the feature folder.
Here’s what SpecFlow+ LivingDoc looks like when published as a TeamCity report:
SpecFlow+ LivingDoc report in TeamCity for the build (without test results)
Our team can view reports from TeamCity, or they can download them to view them locally.
Modifying SpecFlow+ LivingDoc Data
As I mentioned previously in this article, my team and I wanted to share SpecFlow+ LivingDoc reports with some of our customers. We just needed to tweak the contents of the report in two ways. First, we needed to remove scenarios that were inapplicable (meaning not executed) for the bank. Second, we needed to remove certain tags that we use internally at PrecisionLender. Scrubbing this data from the reports would give our customers what they need without including information that they shouldn’t see.
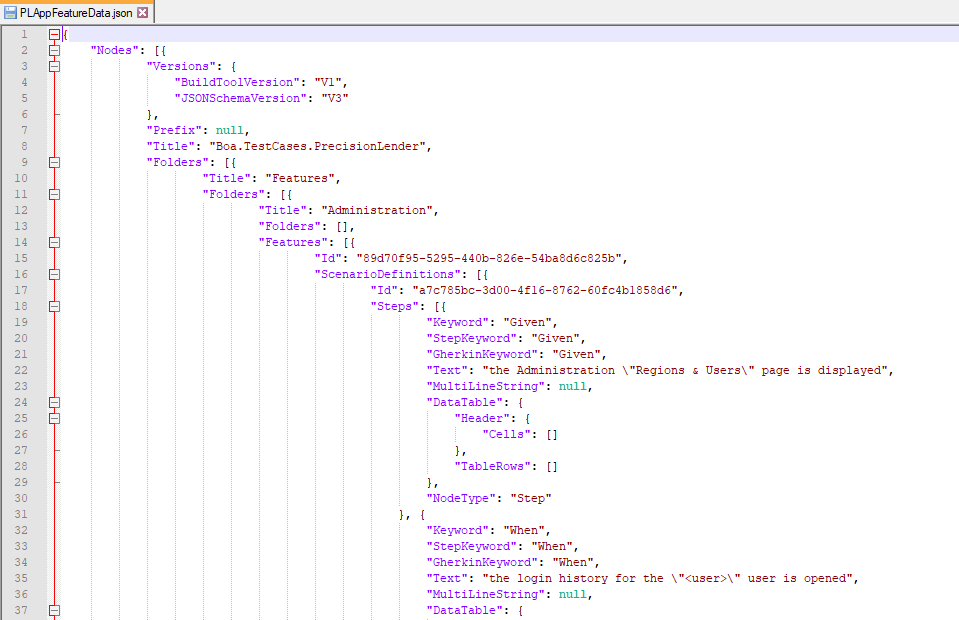
Thankfully, SpecFlow+ LivingDoc has a “backdoor” in its design that makes this kind of data modification easy. When generating a LivingDoc report, you can set the --output-type parameter to be “JSON” instead of “HTML” to generate a feature data JSON file. The feature data file contains all the data for the LivingDoc report in JSON format, including scenarios and tags. You can modify the data in this JSON file and then use it to generate an HTML LivingDoc report. Modifying JSON data is much simpler and cleaner than painfully splicing HTML text.
An example snippet of a feature data JSON file
I wrote two PowerShell scripts to modify feature data. Both are available publicly in GitHub at AndyLPK247/SpecFlowPlusLivingDocScripts. You can copy them from the repository to use them for your project, and you can even enhance them with your own changes. Note that the feature data JSON files they use must be generated from test assemblies, not from feature data folders.
The first script is RemoveSkippedScenarios.ps1. It takes in both a feature data JSON file and a test execution JSON file, and it removes all scenarios from the feature data that did not have results in the test execution data. It uses recursive functions to traverse the feature data JSON “tree” of folders, features, and scenarios. Removing unexecuted scenarios means that the LivingDoc report will only include scenarios with test results – none of the scenarios in it should be “skipped.” For my team, this means a LivingDoc report for a particular bank configuration will not include a bunch of skipped tests for other banks. Even though we currently have over 1400 unique tests, any given bank configuration may run only 1000 of those tests. The extra 400 skipped tests would be noise at best and a data privacy violation at worst.
The second script is RemoveTags.ps1. It takes in a list of tags and a feature data JSON file, and it removes all appearances of those tags from every feature, scenario, and example table. Like the script for removing skipped scenarios, it uses recursive functions to traverse the feature data JSON “tree.” The tags must be given as literal names, but the script could easily be adjusted to handle wildcard patterns or regular expressions.
With these new scripts, our test pipelines now look like this:
Check out the code repository.
Build the Boa test automation solution.
Generate the SpecFlow+ LivingDoc report with unused steps but without test results.
For each applicable bank configuration:
Run appropriate Boa tests and get the test execution JSON file.
Generate the feature data JSON file.
Remove unexecuted scenarios from the feature data.
Remove PrecisionLender-specific tags from the feature data.
Generate the SpecFlow+ LivingDoc report using the modified feature data and the test results.
Below is an example of what the modified LivingDoc report looks like when we run our 12 smoke tests:
SpecFlow+ LivingDoc report using modified feature data after running only 12 smoke tests
(Note: At the time of writing this article, the most recent version of SpecFlow+ LivingDoc now includes a filter for test results in addition to its other filters. Using the test result filter, you can remove unexecuted scenarios from view. This feature is very helpful and could be used for our internal testing, but it would not meet our needs of removing sensitive data from reports for our customers.)
Conclusion
Ever since acquiring SpecFlow from TechTalk in January 2020, Tricentis has done great things to improve SpecFlow’s features and strengthen its community. SpecFlow+ LivingDoc is one of the many fruits of that effort. My team and I at PrecisionLender love these slick new reports, and we are already getting significant value out of them.
If you like SpecFlow+ LivingDoc, then I encourage you to check out some of SpecFlow’s other products. Everything SpecFlow offers is now free to use forever – you just need to register a free SpecFlow account. SpecFlow+ Runner is by far the best way to run SpecFlow tests (and, believe me, I’ve used the other runners for NUnit, xUnit.net, and MsTest). SpecMap is great for mapping and planning stories with Azure Boards. SpecFlow’s Online Gherkin Editor is also one of the best and simplest ways to write Gherkin without needing a full IDE.
Finally, if you use SpecFlow for test automation, give Boa Constrictor a try. Boa Constrictor is a .NET implementation of the Screenplay Pattern that my team and I developed at PrecisionLender. It helps you make better interactions for better automation, and it’s a significant step up from the Page Object Model. It’s now an open source project – all you need to do is install the Boa.Constrictor NuGet package! If you’re interested, be sure to check out the SpecFlow livestream in which Andi Willich and I teamed up to convert an existing SpecFlow project from page objects and drivers to Boa Constrictor’s Screenplay calls. SpecFlow and Boa Constrictor work together beautifully.
Although the news of PyCon’s cancellation is not surprising, it is nevertheless devastating for members of the Python community. Here’s why it hurts, from the perspective of a full-hearted Pythonista, and here’s what we can do about it.
Python is Community-Driven
A frequent adage among Pythonistas is, “Come for the language, and say for the community.” I can personally attest to this statement for myself. When I started using Python in earnest in 2015, I loved how clean, concise, and powerful the language was. I didn’t fully engage the Python community until PyCon 2018, but once I did, I never left because I felt like I became part of something greater than just a bunch of coders.
Python is community-driven. There’s no major company behind the Python language, like Oracle for Java or Microsoft for .NET. Pythonistas keep Python going, whether that’s by being a Python language core developer, a third-party package developer, a conference organizer, a meetup volunteer, a corporate sponsor, or just a coder using Python for projects. And the people in the community are awesome. We help each other. We support each other. We eschew arrogance, champion diversity, and practice inclusivity.
PyCon US is the biggest worldwide Python event of the year. Thousands of Pythonistas from around the world join together for days of tutorials, talks, and sprints. This is the only time that many of us get to see each other in person together. It’s also the only way some of us would have ever met each other. I think of my good mate Julian, co-founder of PyBites. We met by chance at PyCon 2018 in the “hallway track” (meaning, just walking around and meeting people), and we hit it off right away. Julian lives in Australia, while I live in the United States. We probably would never have met outside of PyCon. Since then, we’ve done video chats together and promoted each other’s blogs. We spent much time together at PyCon 2019 and hoped to have another blast at PyCon 2020. We even had plans for a bunch of us content developers to get together to party. Unfortunately, that time together must be postponed until 2021.
There are several other individuals I could name in addition to Julian, too. I’m sure there are several other groups of friends throughout the community who look to PyCon as the time to meet. Losing that opportunity is heartbreaking.
PyCon is a Spectacle
PyCon itself is not just a conference – it’s a spectacle. PyCon is the community’s annual celebration of creativity, innovation, and progress. Talks showcase exciting projects. Tutorials shed deep expertise on critical subjects. Sprints put rocket boosters underneath open source projects to get work done. Online recordings become mainstay resources for the topics they cover. Becoming a speaker at PyCon is truly a badge of honor. Sponsors shower attendees with more swag than a carry-on bag can hold: t-shirts, socks, stickers, yo-yos, autographed books, iPads, water bottles, gloves, Pokémon cards; the list goes on and on. Many sponsors even host after-parties with dinner and drinks. All of these activities combined make PyCon much more than just another conference or event.
PyCon is truly a time to shine. Anyone who attends PyCon catches the magic in the air. There’s an undeniable buzz. And the anticipation leading up to PyCon can be unbearable. It’s like when kids go to Disney World. I can’t tell you how many friends I’ve encouraged to go to PyCon.
At PyCon 2020, we had much to celebrate. Python is now one of the world’s most popular programming languages, according to several surveys. Python 2 reached end-of-life on January 1. There are more Python projects and resources than ever before. 2020 is also the start of a new decade. We can still celebrate them, but not en masse at PyCon this year.
PyCon Supports the PSF
The Python Software Foundation (PSF) is the non-profit organization that supports the Python language and community. Here’s what they do, copied directly from their website:
The Python Software Foundation (PSF) is a 501(c)(3) non-profit corporation that holds the intellectual property rights behind the Python programming language. We manage the open source licensing for Python version 2.1 and later and own and protect the trademarks associated with Python. We also run the North American PyCon conference annually, support other Python conferences around the world, and fund Python related development with our grants program and by funding special projects.
PyCon is a major source of revenue for the PSF. I don’t know the ins and outs of the numbers, but I do know that cancelling PyCon will financially hurt the PSF, which will then affect what the PSF can do to carry out its mission. That’s no bueno.
What Can We Do?
Python is community-driven, and we are not powerless. Here are some things we can do as Pythonistas in light of PyCon 2020’s cancellation:
Support the Python Software Foundation. Openly and publicly thank the PSF for everything they have done. Offer heartfelt sympathies for the incredibly tough decisions they’ve had to make in recent weeks, because they made the unquestionably right decision here.
Join the Python Software Foundation. Anyone can become a member. There are varying levels of membership and commitment. Check out the PSF Membership FAQ for more info. Donations will greatly help the PSF through this tough time.
Engage your local Python community. The Python community is worldwide. Look for a local meetup. Attend regional Python conferences if possible – PyCon isn’t the only Python conference! The closest ones to where I live are PyGotham, PyOhio, and PyTennessee, and I’m helping to re-launch PyCarolinas.
Engage the online Python community. Even though many of us are practicing social distancing due to COVID-19, we can still keep in touch through the Internet. Support each other. Be intentional with good communication. Personally, I started using the hashtag #PythonStrong on Twitter.
Stay safe. COVID-19 is serious. Wherever you are, be smart and do the right things. For folks like me in the United States, that means social distancing right now.
Attend PyCon 2021. Since PyCon 2020 will be cancelled, we ought to make PyCon 2021 the best PyCon ever.
Python Strong
PyCon 2020’s cancellation is devastating but necessary. We shall overcome. Stay safe out there, Pythonistas. Stay #PythonStrong!
Hello World! I’d like to give an update on the PyCarolinas 2020 conference, since we’ve been quiet for quite some time. I’ll share what we’ve done and a new vision for where we want to go, especially given current world events.
How We Got Started
Calvin Spealman founded “PyCarolinas” in 2012 with the first (and so far only) conference at UNC Chapel Hill. The only other Python conference held in the Carolinas since then was PyData Carolinas 2016, hosted by IBM. Despite having several talented Pythonistas in both North and South Carolina, various factors prevented the return of either conference.
I first encountered the Python community when I delivered my first conference talk ever at PyData Carolinas 2016. However, I really became engaged at PyCon 2018, an experience that forever changed my life. I started speaking at several Python conferences around North America. The people I met became dear friends, and the ideas I learned inspired me to be a better Pythonista. However, one thing disappointed me: my home state didn’t have a regional Python conference. I wanted to bring the awesomeness of a Python conference to my backyard so that others could join the fun.
During PyCon 2019, I shared this idea with some friends, and every one of them said that we should make it happen. A few of us attended an open space for conference organizers to swap ideas. Dustin Ingram then invited me to give a call-to-action for a PyCarolinas 2020 conference on the big stage during the “parade of worldwide conferences.” Immediately thereafter, I held an open space for PyCarolinas to kick things off, and dozens of people attended. We created a Slack room, launched a newsletter, and started a Twitter storm. I got in touch with Calvin so we could formally plan things together. Calvin secured a venue at the Red Hat Annex for June 20-21. We even created a logo and took Code of Conduct training by invitation of our wonderful PyGotham friends. Things were looking bright.
Well, What Happened?
Life happened. From November until now, I personally had to handle several personal and family matters, in addition to holidays, my full-time job, and various commitments. You can read the full story here. Calvin also had things come up. As a result, PyCarolinas progress was minimal. We brought together a community, but we failed to meet critical milestones. I personally take responsibility for those failures.
There’s also a new monkey wrench in our plans: COVID-19. The coronavirus is starting to spread throughout the United States, and North Carolina is already in a state of emergency due to multiple local cases. Other conferences like SXSW 2020 and E3 have been canceled. At the time of writing this article, PyCon 2020 might be canceled or postponed. We just don’t know how things will be by June. We would hate to put a lot of work into PyCarolinas 2020 if it could be canceled due to COVID-19, especially when we are already behind schedule.
A New Way Forward
Personally, I was ready to give up and recommend that we cancel PyCarolinas 2020. Then, while returning from PyTennessee 2020, I had a stroke of inspiration:
What if we made PyCarolinas 2020 an “unconference”?
Traditional conferences take a lot of top-down planning and hard commitments, which is not something we can or should do right now. Unconferences, on the other hand, are participant-driven. Their organization is lean: provide a space for people to gather, collaborate, and cross-pollinate.
Here’s the new vision I’d like to cast for a PyCarolinas 2020 Unconference:
One day only: Saturday, June 20 at Red Hat Annex
Lightning talks only: no lengthy CFP; informal sign-ups beforehand
Maybe a keynote speaker
Open collaboration spaces in the other rooms
Set aside time for organizers to seriously plan PyCarolinas 2021
Limit sponsorships for simplicity
Uphold the Python community’s Code of Conduct
Offer only about 100 tickets to keep the event small
Encourage local and regional attendance
Empower the Python community to be awesome!
Furthermore, I would like to offer tickets for FREE! Free tickets would allow anyone to come, and they would also help us as organizers avoid the hassle of money changing hands, bank accounts, and legal entities for this event.
Red Hat has already graciously provided a venue for free. I’d like to find a sponsor to provide pizza and soft drinks for lunch. If possible, I’d also like to find a sponsor to print some stickers.
By keeping this event lean, we win both ways. If COVID-19 is no longer an issue by June, then we get to lead a truly unique type of Python regional conference. If COVID-19 is still a problem, then we can easily postpone the event without much loss or pain.
The Next Steps
I’ve shared this idea with a few friends (including Calvin), and everyone so far agrees that this is a good path forward. In the coming days, we will share this plan to make sure the community agrees. Then, if this is the way, we can launch a very simple website, set up ticketing, and find someone to sponsor pizza.
Personally, I feel good about this idea. It’s a big relief to downsize. Deep down, I know I can trust the Python community to make this unique type of conference a hit.
Python is hot right now. Recently, several people have asked me how they can start learning Python. Here are my answers, nuanced by goals and roles.
I’m completely new to programming. How can I start learning Python?
That’s awesome! Python is a great language for beginners. You can do just about anything with Python, and its learning curve is lower than other languages. Here’s what I recommend:
First, find a friend who knows Python. They can encourage you in your journey and also help you when you get stuck. If you need help finding Python friends, look for a local Python meetup, or just reach out to me.
Second, install the latest version of Python from Python.org onto your computer. If you want to learn Python, then you’ll need to get your hands dirty!
Third, read through a good Python book for beginners. Despite all the material available online, nothing beats a good book. I recommend Automate the Boring Stuff with Python by Al Sweigart. It’s a book written specifically for people who are new to coding, and it shows very practical things you can do with Python. You can even read it for free online! Udemy also offers an online course based on this book. Make sure you follow along with the example code on your own machine.
Once you finish your first book, keep learning! Try another book. Take an online course. Come up with a fun project you can do yourself, like making a website or programming a circuit board.
I’m a hobbyist. How can I start learning Python for fun?
Python is a great language for fun side projects. It’s easy to learn, and it has tons of packages to do just about anything. If you just want to start programming in general, then I’d recommend reading Automate the Boring Stuff with Python by Al Sweigart or Python Crash Course by Eric Matthes. No Starch Press also publishes a number of other Python books on nifty topics like games, math, and ciphers.
If you’re a hobbyist, then my main recommendation would be to come up with a fun project. Learning Python by itself is great, but learning Python to do a cool project will keep you motivated with a clear goal. Here are some ideas:
I’m a software engineer. How can I pick up Python quickly?
If you already know how to code, and you just need to pick up Python for a project on the job, don’t fret. Python will be very quick to pick up. When I re-learned Python a few years ago, I read the Python Programming book on Wikibooks. Learn X in Y Minutes and learnpython.org are also great resources for learning quickly by example. Once you breeze through the language, then you’ll probably need to lear packages and frameworks specific to your project. Some projects have better docs than others. For example, Django and pytest have great docs online.
I’m a scientist. Should I start using Python, and if so, how?
Data scientists were the first scientific community to adopt Python in large numbers, but now scientists from all fields use it for data analysis and visualization. I personally know an environmental scientist and a virologist who both started using Python in the past few years. Compared to other languages like R and Julia, Python simply has more users, more packages, and more support. Furthermore, the Python Developers Survey 2018 showed that over half of all Python users use Python for data analysis. So yes, if you’re a scientist, then you should start using Python!
To get started with Python, first make sure you have basic programming skills. It might be tempting to dive headfirst into coding some data analysis scripts, but your work will turn out much better if you learn the basics first. If you are new to programming, then start by reading Automate the Boring Stuff with Python by Al Sweigart. To learn specifically about data analysis with Python, read Python for Data Analysis by William McKinney. I’d also recommend reading additional books or taking some courses on specific tools and frameworks that you intend to use. Furthermore, I’d yield my advice to any peers in your scientific community who have recommendations.
I’m a software tester. How can I start learning Python for automation?
Python is a great language for test automation. If you are a manual tester who hasn’t done any programming before, focus on learning how to code before learning how to do automation. Follow the advice I gave above for newbies. Once you have basic Python skills, then learn pytest, the most popular and arguably the best test framework for Python. I recommend reading pytest Quick Start Guide by Bruno Oliveira or Python Testing with pytest by Brian Okken. If you want to learn about Test-Driven Development with a Django app, then check out the goat book by Harry Percival.
I’m a kid. Are there any good ways for me to learn Python?
Yes! Python is a great language for kids as well as adults. Its learning curve is low, but it still has tons of power. No Starch Press publishes a few Python books specifically for kids. Project kits from Adafruit and Raspberry Pi are another great way for kids to get their hands dirty with fun projects. If you want to learn by making games, check out Arcade Academy or PursuedPyBear. Many Python conferences also run “Young Coders” events that encourage kids to come and do things with Python.
Should I learn Python, JavaScript, Java, or another language?
Each programming language has advantages and disadvantages, but the main factor in choosing a language should be what you intend to develop. For example, Web app front-ends require JavaScript because browsers use JavaScript and not other languages. Java is popular all around for several applications like backend services and Android apps. C# is a mainstay for Microsoft .NET development. Python excels at backend web development, infrastructure, automation, and data science.
If you are new to programming and just want to start somewhere, I’d strongly recommend Python. Compared to other programming languages, it’s easy to learn. As you grow your skills, Python will grow with you because it has so many packages. You can also explore a variety of interest within the Python community because Python is popular in many domains. These days, you just can’t go wrong learning Python!
Should I learn Python 2 or 3?
Learn Python 3. Python 2 hit end of life on January 1, 2020. Some older projects may continue to use Python 2, but support for Python 2 is dead.
What tools should I use for coding in Python?
The most important tool for coding in any language is arguably the editor or IDE. These days, I use Visual Studio Code with the Python extension. VS Code feels lightweight, but it provides all the things I need as a developer: syntax highlighting, running and debugging, Git integration, and a terminal in the same window. VS Code is also fully customizable. JetBrains PyCharm is another great editor that I recommend. PyCharm a bit heavier than VS Code, but it also has richer features. Both are fantastic choices.
Virtual environments are indispensable part of Python development. They manage Python dependency packages locally per project rather than globally for an entire machine. Local package management is necessary when a user doesn’t have system-wide access or when a project needs a different package version than the one installed globally. To learn about virtual environments, take the venv tutorial in the official Python docs.
Source control is another vital part of programming. Using a source control system like Git maintains a history of your project. If you ever make a mistake, you can revert the code to its last known working state. Source control also makes it much easier for multiple people to work on the same project together simultaneously. Git is one of the most popular source control tools in use today. To learn more about Git, check out GitHub’s learning resources.
What Python books should I read?
Please check my suggestions above to know what Python books could be good for you.
What Python courses should I take online?
To be honest, I don’t have any specific Python courses to recommend. Most online courses are very similar. They include videos, transcripts, quizzes, and maybe even projects. If you want to take an online course, then I recommend finding one that looks good to you and giving it a try. I also recommend using multiple resources – either taking more than one course or reading more than one book. The second pass will reinforce the basics and also reveal new tidbits that the first pass may have missed.
Should I take a Python boot camp?
Boot camps are high-intensity programs that train people to become developers. Many boot camps focus on one main technology stack or skill, such as Web development with JavaScript or data science with Python. They can take weeks or months of full-time focus to complete, and they can be expensive.
Boot camp isn’t right for everyone. Most people go to boot camp in order to find a job after completing the program. They can be a great way to pivot your career if you seriously want to become a software developer but don’t want to go “back to school.” However, they may not be ideal if you just want to learn programming for fun or as a secondary skill.
Personally, I don’t have any boot camps to recommend, but I do know that most major US cities have boot camp programs. If you think boot camp is right for you, then check them out.
Should I go to a Python conference?
YES! Absolutely yes! People come to Python for the language, but they stay for the people. Python conferences are the best way to engage the Python community. They are places to learn and be inspired. You’ll also score tons of cool swag. Lives change at Python conferences.
The main Python conference is PyCon US. Thousands of people attend each year. However, there are several other Python conferences worldwide and regionally around the US. Personally, I’ve been to PyCon, PyOhio, PyGotham, PyCon Canada, PyCaribbean, PyTexas, PyCascades, DjangoCon, and PyData Carolinas. Try to find a regional conference near you if you can’t make it to PyCon.
What are common Python interview questions?
Most interviews I’ve taken focus more on general engineering skills rather than pure language trivia. Nevertheless, if you are pursuing a role that requires Python programming, then you should be prepared for some Python-oriented questions. Online articles like Toptal’s How to Hire a Great Python Developer and Interview Cake’s Python Interview Questions reveal things that a candidate should know about Python.
How much will it cost to use and learn Python?
It’s possible to learn and use Python for free! Python is an open source language. As long as you have a machine with Internet access, you can download Python for free and get rolling. There are tons of free learning resources online, too. Typically, you can learn the basics for free, but you might want to buy some books or courses for specific tools or frameworks.
Friends, I know I haven’t published many blog articles recently. I’d like to give a brief update on things in my life, and I’d also like to share my personal goals for 2020.
Personal Life
My life is busy as ever. Unfortunately, I went mostly dark for nearly two months.
Immediately after hosting Thanksgiving, my wife (Jessica) and I took a two-week trip to China. We spent a week in Shanghai and a week in Taipei. Shanghai was frustrating. We missed a flight to visit Jessica’s family in Shandong province. (Apparently, Jessica’s uncle in the CCP didn’t want to see us anyway because visiting an American might cost him a promotion at his company.) Then, we had to run all over the city to take care of bureaucratic paperwork. Taiwan, on the other hand, was awesome. We did many touristy things: Taipei 101, night markets, Jiufen, Shifen, and Beitou. My favorite part was the National Palace Museum, which houses priceless treasures evacuated from the Forbidden City during the Chinese Civil War.
Linjiang Street Night Market in Taipei, Taiwan
During our time in the East, Jessica and I were also under contract to buy a third house. Jessica wants to invest in more real estate and operate more Airbnb listings. Buying a house is never easy. Closing went well after we returned to the States, but we had to do lots of work to prep the house. I installed a new door and fixed an attic access panel. I changed all the plugs, switches, door handles, and door hinges. Jessica handled all the furniture and decorating. We even drove a new IKEA couch from Baltimore to Raleigh on the roof of my car. We also had to shut down the natural gas over New Years due to a pesky leak. Thankfully, the house is now listed on Airbnb.
Baltimore to Raleigh
At the same time, we did major projects at Jessica’s Mama’s house. We installed a new roof and siding – expensive, but needed. At the same time, we replaced two shower valves because they were leaky. We also installed an electric air unit in the upstairs guest suite. Unfortunately, that project was a nightmare. We needed to hack a new breaker into the electrical panel, and then we discovered that the exterior air unit came broken out of the box. Our next projects will be to paint the house and install gutters.
Home improvement projects at Mama’s house
Immediately after Christmas, my dad fell ill. He spent several days in the hospital. Thankfully, he will make a full recovery.
Needless to say, 2020 got off to a rough start.
Company Buyout
In September 2019, Q2, a banking software company located in Austin, Texas, announced that they would buy my company, PrecisionLender. The deal completed on Halloween. Buyouts can be scary, but thankfully, this one seems okay. I still work on the same team for the same projects. Q2 has showered us with swag. We will still receive our annual bonuses. I even get to take a trip to Austin in February to visit the Quality Enablement team there. I plan to stay at Q2.
The First Half of 2020
I want to focus on speaking engagements for the first half of 2020:
April 15-16: Hands-On Web App Test Automation (tutorial) at PyCon 2020
April 17-19: East Meets West When Translating Django Apps at PyCon 2020
I might have a few more engagements. I also plan to create two more courses for Test Automation University.
The first half of 2020 will culminate in PyCarolinas 2020. I’ve had a dream to bring a regional Python conference home to the Carolinas. Thanks to many friends in the Python community, PyCarolinas will happen this year. We will host it on June 20-21 at the Red Hat Annex in Raleigh, NC. As a co-chair, I will take charge of the program. I hope PyCarolinas will be a great conference, and it should be a fitting milestone for the first half of my year.
PyCascades 2020 action shot (courtesy of @theavalkyrie)
The Second Half
My big goal for the second half of 2020 is to write a book on software testing and automation. I’ve wanted to write a book for years. Now is the time. I want to write a full treatise on the art of software testing. I will write the book’s companion code in Python because I believe that Python is one of the best languages for test automation.
Writing a book is no small task. I will need to say “no” to many good things in order to do this great thing. I plan to step back from conferences while I work on my book (although I’ll still try to attend some favorites). I won’t teach any courses at Wake Tech as an adjunct professor. I probably won’t write many new blog articles during that time, either.
Let’s Go!
2020 will be a busy year. Please encourage me to stay on track! You can follow me on Twitter at @AutomationPanda to keep up with me.
As only New Yorkers know, if you can get through the twilight, you’ll live through the night. (Dorothy Parker)
PyGotham 2018 was my first PyGotham conference and my third conference of the year. I first heard about PyGotham when Jon Banafato and Dan Crosta, two of the organizers, invited me to submit proposals when we met at the PyCon 2018 Instagram dinner. I enjoyed the conference very much, but my experience was much different than the previous two conferences.
A Tourist Day in New York
PyGotham is hosted in New York City. I booked my flight a day before the conference started to make sure that I’d be on time. My wife also came along for the trip. That meant Thursday, October 4 was a tourist day! Our flight arrived in EWR at about 10:30am. We took a commuter train to Penn Station in Manhattan and walked a block to our hotel, Hotel Pennsylvania. Unfortunately, we couldn’t check into our room until 3pm, so we dropped our bags (for $15) and went along our way.
Our first stop was lunch at Xi’an Famous Foods. XFF is a fast casual restaurant chain for authentic Chinese food local to NYC. We ordered two noodle dishes (one liangpi “cold skin” noodles and the other the wide hand-pulled “biang biang” noodles), a pulled pork “burger,” and hawberry tea. Our meal was absolutely delicious.
We spent our afternoon at the National September 11 Memorial & Museum. I was just starting 8th grade when the terrorist attacks happened, but I remembered all the details clearly. The outdoor memorial – a sunken fountain for each tower’s square base – showed both emptiness and resolve. The museum was built into the underground foundations for the towers, essentially as a cave. The starkness of the concrete, the use of light and shadow, and the pacing of exhibits all highlighted the tragedy of 9/11/2001. Every American should visit the site if they are able.
One World Trade Center
The slurry wall
Part of the antenna
We checked into our hotel before dinner that evening. And then we learned why Hotel Pennsylvania has only 2.7 stars on Google: it’s nasty. The hotel is 99 years old and looks like it. The carpets are filthy, the lights are dim, and most of the building smells damp. I chose to stay there because the conference was held there, but I don’t think I will be returning.
One plus side of Hotel PA is that it is right next to Koreatown. My wife and I ate dinner at Five Senses, a trendy Korean restaurant with a line nearly out the door. We then walked around a bit to see the hustle and bustle: we tried Gong Cha bubble tea, got breakfast for the next morning at H-Mart, and bought some face masks at Kosette Beauty Market. A Korean friend of ours was jealous!
Dinner at the Five Senses
A baby octopus!
The Conference
The conference itself lasted two days: Friday, October 5 and Saturday, October 6. About 600 people attended over the two days. By this time, I was well acquainted with Python conference formats. Each day opened with a keynote, followed by several talks in a few rooms with breaks in between. I reconnected with old friends like Trey Hunner and Gabriel Boorse and also made a few new ones.
Trey (left) and me (right)
Gabriel (middle), his friend (left), and me (right)
The opening keynote was “Software Freedom and Ethical Technology” by Karen M. Sandler. Karen explained why free, open source software is foundational for the ethical use and development of technology. She used the example of her Implantable Cardioverter Defibrillator (ICD). Nearly all modern ICDs have wireless connectivity, which renders them vulnerable to hacking. Since the source code in this device and so many others in the Internet of things is closed, individuals are unable to make changes for customization or protection. Karen’s talk was definitely thought-provoking.
My favorite talk, by far, was Trey Hunner’s “Python Oddities Explained”. Trey dove deep into the way variables, data structures, and scope work in Python 3. This talk was particularly helpful for me because I work in several languages and sometimes assume how small details work.
My talk, “Egad! How Do We Start Writing (Better) Tests?“, explained how to build a functional test automation solution in Python from the ground up. It is the same talk I delivered at PyOhio 2018, though I hope it turned out better the second time!
PyGotham had a stronger business vibe than the other Python conferences I attended. Many attendees came as part of company groups. (I heard rumors that about a hundred came from Bloomberg.) Speakers more openly talked about their companies and specific projects. This all made sense considering the location being NYC.
A number of vendors also had tables with goodies to give away. Bank of America, Buzzfeed, Venmo, Linode, Clover, and Django Girls all showed up, along with others I cannot remember off the top of my head. I netted two t-shirts (in addition to two PyGotham t-shirts), a notebook, some silly putty from Linode, and a handful of stickers.
PyGotham 2018!
Sticker addition complete!
The sticker table
After Hours
On Friday night after the conference, my wife and I took the Subway to Brooklyn and walked the Brooklyn Bridge back to Manhattan. The view of the city skyline was spectacular. We then hopped the Subway up to the Upper West Side for drinks with my friend Evan. On the way back to the hotel, we stopped at a dim sum restaurant for a late night dinner.
We didn’t have time to explore New York on Saturday night because we had an overnight flight to catch: we were going to London, England for the week after the conference! We checked out of the hotel, caught the Long Island Rail Road to JFK, and then flew Norwegian Air across the pond.
Dim sum? Dim yum!
Takeaways
During PyGotham 2018, I spent a lot of time pondering software testing and automation. I like to use conferences as my time to disconnect from immediacy and think big thoughts.
One thought I formed was the nuance between testing and change detection. A friend of Gabriel’s posed an idea for REST API service testing. Rather than write a bunch of test cases that check responses, why not simply gather responses and diff them against previous responses? Request automation would still be needed, but response assertions could basically be skipped. Any changes would be identified and reported. This approach struck me as novel and useful but not comprehensive. Change detection will reveal when a code change results in a feature change, but it lacks the moral calculus of true testing because it cannot determine if the change is good or bad. It must yield the judgment to a higher authority, like a developer, a tester, or even an AI agent (which arguably further begs the question of goodness). Nevertheless, I think change detection can be very useful in conjunction with testing, either as a tool to assist manual testing or as an extension to an automation framework.
Another thought I had was to notice the widening gap between companies over testing maturity. Some companies are on the bleeding edge with the latest technologies, tools, and frameworks. They have multi-stage pipelines with countless automated tests and several daily deployments. Other companies are stuck in the past, still suffering through “Agile transformations” and failing tests. There are now several vendors pitching advanced testing solutions, like Sauce Labs for cross-browser testing and Applitools for visual testing. I wonder how many of these vendors are too far ahead for companies with less mature testing to catch up.
For the first time at a conference, I felt serious self doubt. Am I behind the times as a Software Engineer in Test? Is my method of software testing already antiquated? Am I truly a developer, or do I just pretend? Is there a future for the SET role? Will my ideas add value to the field? Will I have time to pursue all of my professional and technical desires? Am I good enough to be here at PyGotham? I felt a bit lonely and withdrawn. My malaise did not sour my conference experience, but it did come unexpectedly. Nevertheless, I must use it as impetus to become a better me.
Final Thoughts
I’m thankful for the opportunity I had to speak at PyGotham 2018. I thank the conference organizers for accepting my talk proposal, as well as PrecisionLender for sponsoring my travel costs. I’d love to return for PyGotham 2019 if possible!