Selenium WebDriver is the most popular open source package for Web UI test automation. It allows tests to interact directly with a web page in a live browser. However, using Selenium WebDriver can be very frustrating because basic interactions often lack robustness, causing intermittent errors for tests.
The Basics
One such vulnerable interaction is clicking elements on a page. Clicking is probably the most common interaction for tests. In C#, a basic click would look like this:
webDriver.FindElement(By.Id("my-id")).Click();
This is the easy and standard way to click elements using Selenium WebDriver. However, it will work only if the targeted element exists and is visible on the page. Otherwise, the WebDriver will throw exceptions. This is when programmers pull their hair out.
Waiting for Existence
To avoid race conditions, interactions should not happen until the target element exists on the page. Even split-second loading times can break automation. The best practice is to use explicit waits before interactions with a reasonable timeout value, like this:
const int timeoutSeconds = 15;
var ts = new TimeSpan(0, 0, timeoutSeconds);
var wait = new WebDriverWait(webDriver, ts);
wait.Until((driver) => driver.FindElements(By.Id("my-id")).Count > 0);
webDriver.FindElement(By.Id("my-id")).Click();
Other Preconditions
Sometimes, Web elements won’t appear without first triggering something else. Even if the element exists on the page, the WebDriver cannot click it until it is made visible. Always look for the proper way to make that element available for clicking. Click on any parent panels or expanders first. Scroll if necessary. Make sure the state of the system should permit the element to be clickable.
If the element is scrolled out of view, move to the element before clicking it:
new Actions(webDriver)
.MoveToElement(webDriver.FindElement(By.Id("my-id")))
.Click()
.Perform();
Last Ditch Efforts
Nevertheless, there are times when clickable elements just don’t cooperate. They just can’t seem to be made visible. When all else fails, drop directly into JavaScript:
Do this only when absolutely necessary. It is a best practice to use Selenium WebDriver methods because they make automated interaction behave more like a real user than raw JavaScript calls. Make sure to give good reasons in code comments whenever doing this, too.
Final Advice
This article was written specifically for clicks, but its advice can be applied to other sorts of interactions, too. Just be smart about waits and preconditions.
Note: Code examples on this page are written in C#, but calls are similar for other languages supported by Selenium WebDriver.
In Gherkin, is it good or bad practice to have multiple Scenario Outlines with Examples tables in one feature file?
The short answer is yes, it is perfectly fine to have multiple Scenario Outlines within one feature file.
However, the unspoken concern with this question is the potential size of the feature file. If one Feature has multiple Scenario Outlines with large feature tables, then the feature file could become unreadable. Remember, Gherkin is a specification language, not a programming language. A feature file should look more like a meaningful behavior example than a giant wall of text or a low-level test script. Make sure to follow good Gherkin guidelines:
Follow the Golden Gherkin Rule: Treat other readers as you would want to be treated.
Follow the Cardinal Rule of BDD: One scenario, one behavior.
Write declarative steps, not imperative ones.
Try to limit the number of steps in each scenario to single digits.
Use only a few rows and columns per example table.
Use, but don’t abuse, the templating facet of Scenario Outlines!
Product quality metrics measure the excellence of a product and its features. They measure the “goodness” inherent in the product, apart from how the product was developed. High-quality processes and tests contribute to, but do not alone guarantee, high-quality products. That’s why quality must be built into the product from the start and checked throughout all phases of development. Below are metrics for assuring quality in the delivered products.
Functionality
Quality Aspect
Does the product work correctly?
Desired State
True – Features either work, or they don’t.
Metrics
Test Failure Rate – The whole purpose of functional testing is to determine which features work and which don’t. Assuming test quality is high, the test failure rate is the single best indicator of product functionality. Higher failure rates mean more broken features. Teams should target low-to-zero test failures. It may be useful to keep a failure history for each test. For large products, it may also be useful to break down failure rates by feature area.
It is imperative to recognize, however, that the test failure rate is meaningful only if test quality is high – meaning that tests have good coverage and reliability. Poor-quality tests will give untrustworthy results. For example, weak coverage could mean that failure rate is low because functionality is not truly exercised, and poor reliability could mean that failure rate is high because tests always crash. Be sure to back up any reporting on test failure rate with assurance that test quality is high (using test quality metrics).
Stability
Quality Aspect
Does the product work reliably?
Desired State
High – Product functionality should be consistently good and available.
Metrics
Build Failure Rate – The build failure rate is the proportion of builds that have failed for whatever reason over a given period of time. While process metrics focus on response times to fix broken builds, the build failure rate itself indicates the health of the product while it is being developed. It does not track how badly a build failed like test failure rate does, but instead it impartially tracks ultimate success or failure. Make sure to limit the history of builds included in the calculation to keep it relevant (such as the last 30 days or so). Occasional build failures are acceptable as long as they are fixed quickly. High build failure rates indicate product instability, which could be due to design flaws, weak pre-check-in testing, tricky bugs, or even pipeline faults.
Uptime – Uptime refers to the total time a system is usable. For example, consider a website that must go down for a one-hour service window every week – its uptime would be 167/168 = 99.4%. Not all downtime is planned, however. A bad deployment during maintenance could knock that website offline for an additional 3 hours – dragging uptime down to 97.6% for the week. This may not seem bad at first, but it’s quite terrible when considering that (a) lost time is lost money and (b) the goal of Six Sigma is 99.99966%. A product should have near-perfect availability. System monitoring tools can easily measure uptime. Low uptime indicates either poor design or lack of failover redundancy.
Performance
Quality Aspect
Does the product work optimally?
Desired State
Optimal – Performance should be at its best in all areas.
Metrics
There are four classic software performance metrics. They may be applied in various ways to aspects of product behavior. Ultimately, software products should have a minimal impact on the system while providing a maximal capacity for work.
Processor Usage – Processor cycles should not be needlessly wasted. Make sure algorithms are efficient in terms of computational complexity (big O) and implementation details.
Memory Usage – Watch out for both memory bloat (when features take up a lot of memory unnecessarily) and memory leaks (when memory is not freed up after it is no longer needed.)
Response Time – Response time, or latency, measures the turnaround time from when an action is taken to when the actor receives feedback that the action is completed. Common examples of response time are web page loading, REST API call responses, and database queries. Response time should be as short as possible.
Throughput – Throughput measures how much load a system can handle. It could refer to data I/O bandwidth, transactions per time unit, number of concurrent users, etc. Typically, higher stress on a system will cause other performance metrics to degrade. The “sweet spot” to find is the maximum throughput value that does not unacceptably impact other performance aspects.
Complexity
Quality Aspect
Is the software code unnecessarily complicated?
Desired State
Minimal – Simple is better than complex. Complex is better than complicated. (See The Zen of Python.)
Metrics
There are a number of code metrics that indicate complexity in various ways.
Lines of Code – One of the most rudimentary metrics is to count the lines of code. All things equal, line count indicates the magnitude of the software product, with the assumption that fewer lines will be easier to maintain. Any modern IDE (or, worst case, shell scripting) can yield line counts. However, all things are not equal, and line count alone does not indicate quality or efficiency.
Cyclomatic Complexity – Cyclomatic complexity measures the number of different execution paths the code can take. It is more meaningful than counting sheer lines of code because it indicates the magnitude of testing needed for full coverage. Lower values are better. Cyclomatic complexity is a popular code metric, and many modern analysis tools can measure it.
Depth of Inheritance – For object-oriented languages, the depth of inheritance measures the maximum length of a class inheritance tree from child class to its ultimate root. For example, in the class inheritance tree of Tiger > Cat > Animal > Object, Tiger would have an inheritance depth of 3. Lower values are desirable because they make classes easier to understand.
There are countless other code metrics available. For example, Microsoft Visual Studio calculates the metrics above plus a maintainability index and class coupling. Halstead metrics are another way to measure complexity.
Satisfaction
Quality Aspect
Does the product satisfy the end user?
Desired State
High – The product should meet the end user’s needs, and the end user should like using it.
Metrics
Customer satisfaction is inherently subjective, so trying to measure it is difficult. Ultimately, the end users must find compelling value in the product over other alternatives, or else they won’t use it or buy it. There are many ways to attempt to gauge customer satisfaction: surveys, interviews, A/B testing, etc. Statistics and psychology also play a part. Check out articles here, here, and here to get some ideas.
Process quality metrics make sure that software development practices build good, high-quality features. Healthy software processes identify and resolve issues as early as possible because later bug discovery means higher cost to fix. Quality starts at inception, when features are first brainstormed, and it carries through design, implementation, and testing. Every step in the development process should have quality checkpoints: acceptance criteria for planning, reviews for design and implementation, and reports for testing. Process quality metrics primarily focus on delivery speed or the effectiveness of feedback loops to make sure a team is responding appropriately to change.
Note: Standard software development methodologies often come with canned metrics. For example, Agile Scrum focuses heavily on velocity for determining a team’s capacity for work, while Agile Kanban focuses heavily on lead time and cycle time for measuring how fast work gets done. This article will not cover methodology-specific metrics – please refer to external resources to learn more about them. Instead, this article will cover generic aspects of process quality.
Delivery Speed
Quality Aspect
How fast are new features with high quality delivered to the end user?
Desired State
ASAP – Deliver them fast without compromising quality.
Metrics
People are impatient – they always want things as soon as possible. Fast delivery speed is thus crucial for businesses to meet client expectations and respond quickly to change. However, delivery speed is not the sole metric for success: it must be counterbalanced with safety measures. Delivery speed could be absolutely minimized by committing changes directly to production, but that’s a terrible practice because the damage risk is too high. The best strategy is to pursue the fastest speed without sacrificing too much coverage.
Time to Production – Time to production focuses on the time it takes for a developer’s checked-in code to become useful to end users. It’s a decent way to judge from a business perspective how quickly new stuff gets out the door. Measure the total time for each code check-in from when it is first committed to when it is deployed to production. Source control logs and deployment histories can be pieced together to measure the total time. It may be beneficial to split check-ins by feature area and to review distributions rather than averages. Short, consistent times are desirable. Long times reveal delays in testing, fixing, and deploying changes.
Pipeline Speed – Pipeline speed is a DevOps-y metric. Measure the total start-to-end time from triggering the build pipeline to the final deployment, and measure the time taken by each stage. This will give insights into bottlenecks, such as: system resource exhaustion, network delays, being stuck in job queues, tests that are too long, etc. Knowing each stage will indicate where the greatest optimizations can occur. For example, parallel test execution can significantly reduce total pipeline time. Use pipeline speed metrics to find efficiencies, not to justify cutting vital stages. Most modern continuous integration systems should provide time metrics.
Test Coverage per Time Period – There is always a tradeoff between test coverage and delivery speed. Assuming tests have optimally efficient execution times, higher coverage means slower delivery. Whenever time periods are fixed (such as CI pipeline limits or release deadlines), the best strategy is to maximize test coverage during the available time. For this purpose, coverage should be heuristically scored in terms of feature coverage priority (or the importance of the behaviors under test), not so much in terms of numerical code coverage. Then, for each test, divide the coverage score by the execution time. Sort tests by this ratio, and select the tests with the greatest scores until the total test execution time reaches the time limit. This approach guarantees that maximal test coverage will be achieved in the given period. It may also be advantageous to determine a threshold score for minimal coverage – if the maximum score for a given time period is below the minimal coverage threshold, then the time period should be increased. This metric is compelling if, for example, a CI pipeline needs more time for tests but managers are hesitant to slow down delivery.
Note: The metrics here cover speed after code is checked in, focusing on operational excellence. Metrics covering speed before code is checked in are important but are typically already covered by standard processes (like Scrum’s velocity). There are several ways to measure speed before code check-in: development time, backlog age, story completion rate, etc. Slow times before check-in indicate that a team is overloaded with work, lacks focus on priorities, or is being disrupted too frequently. However, one major caution for these metrics is that they are difficult to accurately measure, and they presume artifacts are logged precisely at event times. For example, if a story ticket is not created until a week after a new feature was first inspired, then the actual times measured will be inaccurate.
Feedback Notification
Quality Aspect
How quickly does a team identify problems?
Desired State
Fast – Fast feedback helps teams resolve issues quickly before they become more costly.
Metrics
Software development is the poster child for Murphy’s Law: anything that can go wrong will. Problems will happen. Metrics targeting perfection (such as 100% pass rates or 0-bug counts) are foolishly impossible and hopelessly destructive. Instead, metrics should gauge feedback loops – how well a team handles problems as they arise. Feedback has two parts: (1) notification time to discover and report problems, and (2) response time to fix problems. Ultimately, the sum should be minimal, but separating the parts identifies bottlenecks. This section covers notification.
Code Review Effectiveness – Code reviews are often the second line of defense against bugs (the first line being the author themselves). They grant an opportunity for other experts to inspect code for problems before fully committing changes. However, measuring the effectiveness of code reviews can be tricky. A few metrics to consider are:
Percentage of code check-ins that undergo review, if the team notoriously skips reviews
Average review turnaround time, if reviews are ignored
Code change size in terms of line number or another similar unit, if reviews are too large for teams to handle effectively
Issues caught, whenever a review successfully identifies and resolves an issue
Issue Discovery Time – The sooner issues are discovered, the less costly they are to resolve. “Issues” typically mean defects in the product (e.g., “bugs”), but they could include problems with the environment, deployment, or tests. The simplest form of issue discovery time is the measurement from when a pipeline starts to the time the issue is discovered. More advanced measurements can track time back to the root cause, such as when code containing a bug was committed, but these may be difficult to gather or may be less accurate. Issue types should be analyzed as separate distributions. Look specifically for blocking issues that appear late in the pipeline, such as critical services being down, and add checks early in the pipeline to discover them ASAP.
Bugs per Phase – Raw bug counts, like test counts, are not helpful beyond soundbites, but the proportions of bug counts per phase are useful for determining test effectiveness. A well-engineered pipeline should have meaningful phases (or “stages” or “steps”) with feedback after each one. A typical pipeline could have phases for build, unit tests, integration tests, end-to-end tests, and production deployment. Ideally, bugs should be caught in the shortest time, at the lowest level, and in the earliest phase. For example, if the majority of bugs are caught by end-to-end tests or (gasp!) in production, then the lower-level tests might need stronger coverage.
Feedback Response
Quality Aspect
How quickly does a team resolve problems once they are found?
Desired State
Fast – Again, resolve issues quickly before they become more costly.
Metrics
Time to Fix a Broken Build – Build health is vital for successful software development, especially in continuous integration. After a build is broken, it must be fixed ASAP so that it does not block progress. “Fixing” a build means that the pipeline can run to completion with an acceptable test passing rate. Fixing a build may mean:
Fixing a bug in the product
Fixing a problem in the environment, deployment, or tests
Reverting a code check-in that caused a bug
Updating tests to somehow flag the failure
Subverting safety checks (like removing tests or skipping phases) is not acceptable because it doesn’t truly fix the build’s underlying problems.
Measure the time it takes from when a pipeline reports a broken build to when the pipeline produces the first subsequent working build. The distribution of these times will reveal the team’s dedication to build stability. Clearly, shorter times are better. When broken builds are caused by code changes, the author should favor reverting check-ins over attempting fixes for faster recovery speed.
Time to Resolve Bugs – While the time to fix a broken build focuses on immediate product stability, the time to resolve bugs focuses instead on ultimate correctness. Just because a build is fixed does not mean a bug is necessarily fixed – tests may mark it as an acceptable failure, or the code containing the bug may simply be reverted. The time to resolve a bug is the total time from when the bug was first discovered to when it is fixed or otherwise closed (such as being marked as invalid or won’t fix). Bug tracker tools should easily provide this data. Bugs should be separated by severity when analyzing resolution times. Bugs should be resolved quickly, with priority given to higher-severity bugs. Resolution time metrics indicate if bugs are addressed adequately and in the proper order. Long resolution times may indicate overloaded teams, tolerance of low quality, or the need for redesign/refactoring.
Test quality metrics make sure that testing efforts are worthwhile. Though “testing” and “quality” may be synonymous as organizational titles, testing is only one method of enforcing quality. In software, it just happens to be the most effective one. Testing is expensive, though, because it slows down time-to-market. Some people even devalue testing work because it doesn’t add new features to a product. Below are aspects of test quality to consider measuring to prove and even increase the value of testing efforts.
Coverage
Quality Aspect
How much functionality is covered by tests?
Desired State
High – More coverage means less risk. Note that 100% complete coverage is impossible.
Metrics
Coverage may be measured for both manual and automated tests. However, automated test coverage is usually more important because automated tests are meant to be defensive without gaps.
Code Coverage – Code coverage tools check what paths of code are actually exercised by automated tests. While they cannot tell if tests are good or bad, they are great for exposing gaps in coverage. Unit test code coverage is easy because most frameworks have plugins, but above-unit code coverage requires instrumented builds. Look for tools that track more than just lines of code. Target 90%+ coverage. Add new tests to cover any major gaps.
Feature Coverage – Feature coverage is a manual way to score features on test coverage based on planning and review. For this metric to be successful, a team must consistently specify features well; otherwise, this metric will give useless data. Gherkin scenarios a great way to do this – for example, each scenario can be marked as untested, manual, or automated. Feature coverage is unscientific, but it can give a better picture of functionalities actually covered (instead of just the raw lines of code covered).
Automation Debt – Technical debt increases when tests are not automated and thus lack coverage. Teams are often unable to automate all tests originally planned, and test automation is frequently jettisoned from the Definition of Done. Or, a project may not start automating tests until a large chunk of the project is already complete. The best way to track automation debt is to create a backlog for incomplete automation work. Backlog tasks can be sized, prioritized, and planned according to whatever development process is used (Scrum, Kanban, etc.). Appropriate process metrics can then be used to understand the magnitude of the work and, thus, the lack of automated test coverage.
Warning: Test case count, test length, and test code line count are terrible metrics for coverage because they encourage largeness rather than uniqueness. The goal of testing is to have the greatest coverage with the lowest risk for the least work. Anybody can blindly write tests or variations that add no meaningful value.
Reliability
Quality Aspect
Do automated tests consistently reach completion? And how trustworthy are the results?
Desired State
High – Reliability means less time for failure triage or (horrors) reruns.
Metrics
Failure Reasons – Track the failure reason for each test case run. Ideally, tests should fail only when they discover product bugs. However, tests may also fail when:
an acceptable product change caused an automation error because tests were not updated, indicating poor communication or careless updates
an environmental change or interruption caused an automation error, indicating deployment or sysadmin problems
the automation code itself has a bug
Remember, “successful” test runs either pass with appropriate coverage or fail due to product bugs. “Unsuccessful” test runs fail or crash for reasons other than product bugs. Aim to minimize unsuccessful test runs. Never hack a test just to get it passing – always work to fix the problems behind test failures.
Speed
Quality Aspect
How much time do test runs take?
Desired State
Fast – Tests should complete in the shortest time possible.
Metrics
Test Case Execution Time – Test case execution times indicate the efficiency of the automation code. Track the start-to-end execution time for every individual test case run. Then, analyze the data using common sense. For example, outliers may be inefficient tests that need tuning or should be removed altogether. It may be wise to separate test runs by result type or coverage area. Historical data can also be used as a baseline to determine performance impacts when making cross-cutting automation changes.
Test Suite Execution Time – Test suites are sets of test cases, but their execution times are not merely the sum of their tests’ times. A test suite run may include environmental setup, deployment, parallel execution, reporting, and other things. The purpose of tracking test suite execution time is to determine the start-to-end time of the suite in total, because that indicates the speed of feedback and, in CI, delivery. Tracking test suite execution time will also reveal the effect of adding more test cases to the suite, which then factors into the risk-based decisions of including or excluding tests.
Test Pyramid Balance – The Test Pyramid separates tests between unit (bottom), integration (middle), and end-to-end (top) layers. Ideally, there should be more tests at the bottom than at the top. Why? Higher-level tests are more expensive – they take more time to develop, they are more time consuming to triage, and they have slower execution times. Consider the “Rule of 1’s”: a unit test takes ~1ms, an integration test takes ~1s, and an end-to-end test takes ~1m. When scaled to thousands of tests with continuous integration, end-to-end tests simply take too much time. Tracking the proportion of tests at each layer will give a rough picture of the balance. There’s no perfect ratio between layers, but make sure that the tests form a pyramid and not a cupcake, hourglass, or ice cream cone. Rebalance test efforts as appropriate.
Return on Investment
Quality Aspect
Do the tests add greater value than their cost?
Desired State
High – Tests need to be worth the effort. Don’t test for the sake of testing!
Metrics
Measuring return on investment in terms of hard dollars is objectively impossible. The true cost of bugs can never be fully known: if a bug is caught early, the potential cost to fix it later can merely be estimated. The intangible value of protecting brand reputation may be more important than the tangible value of money saved by finding specific bugs. Better quality practices might prevent developers from causing bugs that would have otherwise happened – and there’s no good way to measure that.
Instead, return on investment is better measured by a collection of metrics that validate both code line protection and defect discovery. Use a weighted scorecard to get a more holistic view of ROI. Scorecards can be used with estimates for planning tests, as well as plugged in with actual values to measure the degree of success. Note that some aspects of ROI may be too difficult to measure accurately – in those cases, a LOW-MID-HIGH grading scale may be best. Others may seem like micromanagement.
Priority – Assign each test a priority for its coverage importance. Core functionalities should have the highest priority, while fringe functionalities should have the lowest priority. Focus on high-priority tests. Another way to look at importance is risk, or the chances that bugs will escape if explicit testing for a feature is not done.
Test Execution Frequency – Track how many times tests are actually run. Higher frequency is better. Tests that are rarely run should either be included in more regular runs or removed/archived. This could easily be tracked by a test management tool or database.
Coverage Uniqueness – Duplicate test coverage wastes resources. Unfortunately, this one is difficult to measure. Tools for code coverage or static analysis might help. Manual review, however, is typically a better approach.
Development Cost and Maintenance Cost – Track how much effort it takes to make and keep tests, including man-hours and resources. Lower costs are better, of course. Planning tools may help with this.
Bug Discovery – Track bugs discovered in terms of severity and when and how they were caught. Ideally, the number of bugs caught by customers after a release (meaning, not caught by tests during development) should be minimal, and their severity should be low. Bug tracking tools should easily provide this data. Be warned, though, that the raw bug count is a poor metric. Consider this question: Is a high bug count good or bad? Trick question – during a release, it indicates good test quality but poor product quality; after a release, it indicates all-around poor quality. What matters is that a minimal number of bugs happen at all, and that most of those bugs are caught and fixed before a release. Plus, keep in mind that bugs happen by accident. Finally, focusing exclusively on bug count to determine test value ignores the positive side of testing – that passing tests give confidence that features work correctly.
When developing software, metrics can be a good way to track progress and evaluate quality. Managers typically love them because they provide insights that could otherwise be hard to see. Come on, who doesn’t love pretty charts with rainbow colors? However, gathering metrics is not easy, especially for quality. Some metrics are downright useless, and others encourage bad behavior when used improperly. It is far more important to focus on the most important aspects of quality than to blindly promulgate numbers. This article will cover quality metrics in depth, giving guidance on what quality aspects matter most and how they can be measured.
What are Quality Metrics?
Quality is the degree of a feature’s excellence. Quality metrics attempt to impartially measure a feature’s excellence. The word “attempt” is notable – quality is inherently relative, and metrics can sometimes be subjective. Take pizza as an example: How would the quality of a pizza be measured? One method could be to analyze the freshness and nutritious value of the ingredients, but, Pizza Hut notoriously fought Papa John’s Pizza over the assertion that better ingredients make better pizza. Another method could be to analyze the cooking process, like bake time or the order of toppings, but that would be better for identifying carelessness than quality. The delivery process could also be considered, like Domino’s delivery robots, but that evaluates customer service and not the pizza itself. Ultimately, what matters are the taste and the visual appearance, which are totally subjective to the consumer. Surveys are unreliable. Taste tests have limited selection. Appearance is an art, not a science. Each of these metrics gives a glimpse into quality but does not fully reveal what actually makes a “good” pizza. Together, though, they provide a reasonable picture when the desired metrics are gathered well.
Is that really high quality pizza? Well, what aspects of quality are we measuring? We won’t get a perfect picture of quality from metrics, but we can get a rough idea. Software quality metrics work the same way.
Software Quality
In software, there are three primary types of quality metrics:
Examples: test failure rate, up-time, customer satisfaction.
The main purpose of software quality metrics is to validate successes and find areas for improvement in the development process. Metrics expose problems like gaps in coverage or slow feedback loops so that a team knows what to improve. They are meant to be informative but not punitive – they should simply report accurate data. Don’t shoot the messenger! For example, if the test failure rate is high, fix the bugs instead of blaming each other.
However, be warned by W. Edwards Deming‘s red bead experiment: Quality cannot be inspected into a product – it must be built in from the beginning! Metrics alone cannot solve problems – they can merely expose them. It is up to the development team to affect the proper change based on what metrics reveal. Awareness is useless without action. And action should ultimately lead to better features, faster delivery, and higher profits.
Choosing Quality Metrics
Metrics are nothing but tools to improve aspects of quality. Not every job needs the full toolbox! Always pick the quality aspect first, and then find the right measuring stick. Don’t just pick some metrics that others say are good. For example, if build stability is the quality aspect that is deemed important (and it should be), then the metric to track it could be the average time to fix a build after it is broken.
The best process for choosing quality metrics is:
Identify a quality aspect that adds value.
Decide if the aspect is worth measuring.
Determine the desired state for that aspect.
Derive the best way to measure progress toward the desired state impartially.
Implement the metric gathering, storage, and analysis.
Revisit the metric periodically to assert its value.
Stop gathering the metric when it ceases to provide value.
Keep in mind that metrics have a cost: they must be gathered, stored, and analyzed. That’s why it’s important to pick the quality aspects that matter most.
This Series
The articles in this series will cover each of the quality metric types in detail. Each will list major quality aspects with meaningful metrics to track them and advice on how to use them. Remember, metrics should be constructive and not destructive.
Writing Gherkin is easy, but writing good Gherkin is hard. My post BDD 101: Writing Good Gherkin covers many aspects of good behavior specification, including titles, phrasing, and data. One of the major points I make anytime I discuss good Gherkin is what I call the “Cardinal Rule of BDD.”
The Cardinal Rule of BDD: One Scenario, One Behavior!
A behavior scenario specification should focus on one individual behavior. This is the essence of the BDD mindset – a product’s features can be specified in terms of its behaviors, and the specs should be written as examples of those behaviors in action. Identifying individual behaviors brings clarity to design, development, and testing. Combining behaviors into a single scenario causes ambiguity, miscommunication, and test gaps. Test failure triage also becomes more difficult and time consuming because the root causes for failures are less clear – the culprit could be one of multiple behaviors. There is also a high risk of duplication when scenarios repeat the same sequence of steps instead of isolating behaviors.
One of the dead giveaways to violations of the Cardinal Rule of BDD is when a Gherkin scenario has multiple When-Then pairs, like this:
Feature: Google Searching
Scenario: Google Image search shows pictures
Giventhe user opens a web browser
Andthe user navigates to "https://www.google.com/"Whenthe user enters "panda" into the search bar
Thenlinks related to "panda" are shown on the results page
Whenthe user clicks on the "Images" link at the top of the results page
Thenimages related to "panda" are shown on the results page
A When-Then pair denotes a unique behavior. In this example, the behaviors of performing a search and changing the search to images could and should clearly be separated into two scenarios, like this:
Feature: Google Searching
Scenario: Search from the search bar
Given a web browser is at the Google home page
When the user enters "panda" into the search bar
Then links related to "panda" are shown on the results page
Scenario: Image search
Given Google search results for "panda" are shown
When the user clicks on the "Images" link at the top of the results page
Then images related to "panda" are shown on the results page
Despite being so central to BDD philosophy, the Cardinal Rule is the one thing people always try to sidestep. Nobody ever doubts the usefulness of step parameters or the need for good grammar, but people frequently show me scenarios with multiple When-Then pairs and basically ask for an exception from the rule. My gut reaction is always, “NO! Rules don’t change.”
However…
I must first admit that the Cardinal Rule of BDD is “opinionated” – it is the way that I have found BDD to work best for collaboration and automation. Adherence forces people to adopt a behavior-driven mindset, and strictness keeps feature and test quality high. Other experts are more permissive of multiple When-Then pairs, though. Most examples I could find from leading sources such as The Cucumber Book exhibit strict Given-When-Then order for Gherkin scenarios, but other sources such as the online JBehave documentation show scenarios with multiple When-Then pairs boldly on the front page.
I must also begrudgingly admit that there are times when it is simply more convenient for a single scenario to have multiple behaviors (and thus multiple When-Then pairs). This is by no means a best practice but rather a pragmatic alternative for specification dilemmas. (See Purist vs. Pragmatist.) Below are situations in which multiple When-Then pairs may be acceptable.
Lengthy End-to-End Scenarios
End-to-end tests verify execution paths through a live system with all of its parts. Web UI tests frequently fall into this category: Selenium WebDriver interacts with a page in a browser, which then triggers calls to a backend service layer or database. Despite the name, end-to-end tests may still focus on one individual behavior. The example scenarios above, though short, technically count as end-to-end tests.
However, many people use the term “end-to-end” to refer to tests that cover sequences of behaviors. Such a scenario could violate the Cardinal Rule of BDD if it is not handled carefully. My article BDD 101: Unit, Integration, and End-to-End Tests gives strategies for handling lengthy end-to-end scenarios. One strategy is to simply turn a blind eye to multiple When-Then pairs. Ideally, each behavior would already have its own individual scenario, but then a new scenario would explicitly combine the behaviors together to get that full, end-to-end path. The new scenario would be easy to write because the steps could be reused. This isn’t the only strategy, so please be sure to consider the others before writing the tests.
Audits
Software system audits frequently require lengthy end-to-end scenarios. They are quite common in highly-regulated domains. For example, a bank may need to prove that a loan is prepared correctly or that a transaction puts money into the right accounts. Auditors typically require tests to run through entire system paths (e.g., multiple behaviors) using the same records, such as one loan application or one payment. Auditees must not only provide test results for past runs but must also repeat tests on demand. Separating each individual behavior into its own scenario makes each test independent, so during test execution, there will be no guaranteed order and no shared test data, and auditors would not have the end-to-end verification that they require. The simplest way to give the auditors what they need is to write one lengthy scenario with multiple When-Then pairs.
Service Calls
Service call testing is another case for which multiple When-Then pairs may be pragmatically justified. REST, SOAP, and WSDL are examples of service call types. Service layer development is more engineering-centric than business-centric, but many teams nevertheless choose to test service calls with Gherkin-based frameworks like Cucumber. Due to the programmatic nature of services, Gherkin scenarios for service calls tend to be quite imperative: specify a request, make the call, and verify parts of the response. This isn’t so bad for independent service calls, but it becomes a problematic when one request needs another call’s response.
One solution is the classic “pure” scenario split: put any necessary setup, including initial requests to get required response parts, into custom Given steps. This abides by the Cardinal Rule and avoids duplicate When-Then pairs. But, it introduces an unsavory form of code duplication. Many service calls end up being written twice: once as a Gherkin scenario for testing, and once in the underlying automation code to be called by Given steps. This violates the DRY principle.
The alternative “pragmatic” solution is to write scenarios that specify multiple service calls in the Gherkin steps. The Karate project advocates this approach, as shown in their “Hello World” example:
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters. Learn more about bidirectional Unicode characters
There may be other cases when When-Then repetition is useful. Feel free to leave suggestions in the comments below. My examples are meant to be descriptive, not prescriptive. Another aspect to consider is that allowing multiple When-Then pairs per scenario indicates that a team sees more value in BDD’s test framework than in its collaborative spec process. (Refer to ‑‑BDD; Automation without Collaboration and BDD‑‑; Collaboration without Automation.)
Ultimately, you must decide what practices are best for your project. The main reason I uphold the Cardinal Rule of BDD so strongly is that it makes for good specs and good tests. I’ve seen engineers write extremely long, intensive test procedures (and I mean, dozens of duplicate behaviors per test) that are alright for manual testing but do not transition well into automation because they are too fragile and they don’t yield useful information upon failure. The Cardinal Rule is a way to break out of the procedure-driven mindset, and banning multiple When-Then pairs per Gherkin scenario is an effective rule for enforcing it.
Treat other readers as you would want to be treated. Write Gherkin so that people who don’t know the feature will understand it.
Part of writing good Gherkin (or any other specification-by-example language) includes writing good behavior scenario titles. The title is the face of the scenario: it summarizes what the behavior is all about. Good titles make collaboration and test triage a breeze, whereas bad titles make it tougher. But what makes a title “good”? Below are some helpful pointers.
Good Titles from Good Tests
Writing good titles is easy for well-written scenarios. A good Gherkin scenario concisely focuses on one distinct behavior. If you are struggling to think of a good title, perhaps you should take a step back and ask, “Is this scenario a good scenario?” Check out my article, 4 Rules for Writing Good Gherkin, or Paul Merrill’s article, 5 ways to simplify your automated test cases, to help you write great scenarios.
One-Liners
Good titles should be short one-liners. One simple statement should be sufficient to concisely capture the intended behavior. Anything longer likely means that either the author doesn’t truly understand the behavior in focus, or that the scenario does not focus on one main behavior. Extra comments may be added to supplement the scenario’s description if necessary to avoid lengthy titles. Also, most BDD test automation frameworks will print scenario titles to logs for traceability.
Bad Example
Good Example
The user can log into the app, navigate to the profile page, and see their full name, address, phone number, email, and username
The profile page displays the user’s personal info
Conjunction Disjunction
Watch out for conjunction words like “and,” “or,” and “but.” Conjunctions typically imply that more than one thing will be done, which for scenario titles implies that more than one behavior will be covered. Or, it indicates that a Scenario Outline may be appropriate Don’t break the Cardinal Rule of BDD! Keep each scenario focused on one main behavior.
Avoid other conjunctions like “because,” “since,” and “so” as well. Phrases starting with those words often give an explanation for why the scenario exists. However, for conciseness, scenario titles should focus on what the behavior is. The why can either be deduced from the steps or made plain with comments.
Bad Example
Good Example
The user can request an insurance quote from the big “Get-A-Quote” button on the home page or from the “Insurance Policies” page
Two Scenarios: The user requests an insurance quote from the “Get-A-Quote” button on the home page / The user requests an insurance quote from the “Insurance Policies” page
-OR-
Scenario Outline: The user requests an insurance quote
The last five search phrases are saved so that the user can rerun them from the history page
The history page saves the last five search phrases
Avoid Assertion Language
Don’t use the words “verify,” “assert,” or “should” in scenario titles. They put the scenario’s emphasis on the assertion rather than the behavior. Assertions are merely a facet of behavior testing – they verify that something exists or that two values are equal. Behavior scenarios, however, are full software specifications. BDD is a development practice for making better software products – it’s not just a test tool. Don’t reduce the behavior-driven mindset to a test-only mindset.
Furthermore, leading every scenario title with “verify” or “assert” becomes very repetitive. The words just don’t enhance the meaningfulness of the title. They also thwart alphabetical order.
Bad Example
Good Example
Verify the user can change their address on the profile page
Profile page address change
Assert that a stock quote is displayed in green text when its value is higher than its previous closing value
A stock quote has green text when its value is higher than its previous closing value
The goodbye page should be displayed after a successful logout
Logout displays the goodbye page
Do you have any more suggestions? Put them in the comments below!
This post was originally published by Sealights on December 19, 2017 as part of their article Test Quality in CI/CD – Expert Roundup. I was honored to contribute my thoughts on automatic recovery in test automation, and I reblogged the text of my contribution here for Automation Panda readers. Please check out contributions from other experts in the full article!
Test automation is an essential part of CI/CD, but it must be extremely robust.
Unfortunately, tests running in live environments (integration and end-to-end)
often suffer rare but pesky “interruptions” that, if unhandled, will cause tests to fail.
These interruptions could be network blips, web pages not fully loaded, or
temporarily downed services – any environment issues unrelated to product bugs.
Interruptive failures are problematic because they (a) are intermittent and thus
difficult to pinpoint, (b) waste engineering time, (c) potentially hide real failures,
and (d) cast doubt over process/product quality. Furthermore, CI/CD magnifies
even rare issues. If an interruption has only a 1% chance of happening during a test,
then considering binomial probabilities, there is a 63% chance it will happen after
100 tests, and a 99% chance it will happen after 500 tests. Keep in mind that it is not
uncommon for thousands of tests to run daily in CI – Google Guava had over 286K
tests back in July 2012!
It is impossible to completely avoid interruptions – they will happen. Therefore, it is
imperative to handle interruptions at multiple layers:
First, secure the platform upon which the tests run. Make sure system
performance is healthy and that network connections are stable.
Second, add failover logic to the automated tests. Any time an interruption
happens, catch it as close to its source as possible, pause briefly, and retry the
operation(s). Do not catch any type of error: pinpoint specific interruption
signatures to avoid false positives. Build failover logic into the framework
rather than implementing it for one-off cases. For example, wrappers around web element or service calls could automatically perform retries. Aspect-
oriented programming can help here tremendously. Repeating failed tests in their entirety also works and may be easier to implement but takes much
more time to run.
Third, log any interruptions and recovery attempts as warnings. Do not
neglect to report them because they could indicate legitimate problems,
especially if patterns appear.
It may be difficult to differentiate interruptions from legitimate bugs. Or, certain
retry attempts might take too long to be practical. When in doubt, just fail the test –
that’s the safer approach.
Do you want to add a favicon to your Django site the right way? Want to add it to your admin site as well? Read this guide to find out how!
What is a Favicon?
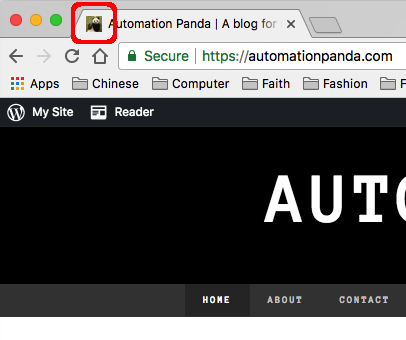
A favicon (a.k.a a “favorite icon” or a “shortcut icon”) is a small image that appears with the title of a web page in a browser. Typically, it’s a logo. Favicons were first introduced by Internet Explorer 5 in 1999, and they have since been standardized by W3C. Traditionally, a site’s favicon is saved as 16×16 pixel “favicon.ico” file in the site’s root directory, but many contemporary browsers support other sizes, formats, and locations. There are a plethora of free favicon generators available online. Every serious website should have a favicon.
The favicon for this blog is circled above in red.
Making the Favicon a Static File
Before embedding the favicon in web pages, it must be added to the Django project as a static file. Make sure the favicon is accessible however you choose to set up static files. The simplest approach would be to put the image file under a directory named static/images and use the standard static file settings. However, I strongly recommend reading the official docs on static files:
Adding the favicon to a Django web page is really no different than adding it to any other type of web page. Simply add the link for the favicon file to the HTML template file’s header using the static URL. It should look something like this:
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters. Learn more about bidirectional Unicode characters
Most sites use only one favicon for all pages. Rather than adding the same favicon explicitly to every page, it would be better to write a parent template that adds it automatically for all pages. A basic parent template could look like this:
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters. Learn more about bidirectional Unicode characters
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters. Learn more about bidirectional Unicode characters
As good practice, other common things like CSS links could also be added to the parent template. Customize parent templates to your project’s needs.
Admin Site Favicon
While the admin site is not the main site most people will see, it is still nice to give it a favicon. The best way to set the favicon is to override admin templates, as explained in this StackOverflow post. This approach is like an extension of the previous one: a new template will be inserted between an existing parent-child inheritance to set the favicon. Create a new template at templates/admin/base_site.html with the contents below, and all admin site pages will have the favicon!
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters. Learn more about bidirectional Unicode characters
Make sure the template directory path is included in the TEMPLATES setting if it is outside of an app:
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters. Learn more about bidirectional Unicode characters
The Django REST Framework is a great extension to Django for creating simple, standard, and seamless REST APIs for a site. It also provides a browsable API so that humans can easily see and use the endpoints. It’s fairly easy to change the browsable API’s favicon using a similar template override. Create a new template at templates/rest_framework/api.html with the following contents:
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters. Learn more about bidirectional Unicode characters
A number of other articles (here, here, and here) suggest adding a URL redirect for the favicon file. Unfortunately, I got mixed results when I attempted this method myself: it worked on Mozilla Firefox and Microsoft Edge but not Google Chrome. (Yes, I tried clearing the cache and all that jazz.)
Django Favicon Apps
There are open-source Django apps for handling favicons more easily. I have not used them personally, but they are at least worth mentioning: