Warning #1: This post has nothing to do with software development or testing. It is purely a post for my own pleasure.
Warning #2: SPOILER ALERT! This post is full of ’em.
The Legend of Zelda: Breath of the Wild is one of my favorite video games. Ever. I’ve been playing it regularly on my Wii U since Christmas, and I just beat the main quest. I redeemed all four Divine Beasts, found all 120 shrines, recovered all memories, and got a majority of the Korok seeds and Hyrule Compendium. It was truly the (virtual) adventure of a lifetime! In celebration of finally beating the game, I’m going to retrospect on what I loved about it so much.
What’s It About?
If you don’t know what this game is about, watch this:
Here’s the story: You, as a young man named Link, wake up in a cave with no memory about yourself or your past. As you explore the world and recover your memories, you discover that the kingdom of Hyrule was destroyed 100 years ago by the evil Calamity Ganon. Princess Zelda has sealed Ganon inside Hyrule Castle since then, but her power is weakening. You, along with four other “champions,” fought together to defeat Ganon but failed, and you yourself were nearly killed. Your main mission is to explore the land to strengthening yourself, recover lost memories, and reawaken four divine beasts. Then, you need to storm the castle to defeat Ganon, rescue Zelda, and bring a lasting peace to Hyrule.
How I Played
When BOTW was first announced as an open-world adventure, I immediately shut out all news and reviews aside from official trailers. I adamantly did not want any spoilers whatsoever. I wanted to fully explore the game on my own. And, truth be told, it was totally worth it.
When I play video games, I tend to be a completionist. I like to leave no stone unturned, and I take time to power up as much as possible before big challenges. As a result, my progress rate in BOTW was rather slow, but I feel like I didn’t miss out on anything. Even then, there are still side quests left incomplete and Korok seeds left unfound. All told, I spent 241 hours on a single save file.

My total playtime after defeating Ganon.
After completing the Great Plateau and fully restoring the Sheikah Slate, my main approach to exploration was to look for shrines in a new area using the binoculars, make a mad rush for the shrine to claim a safety post, and then thoroughly search the surrounding areas for new stuff. I literally went around blind because I didn’t know where to find the Divine Beasts. Here’s roughly the path I took:
- Scoured Necluda for shrines for a while.
- Went to Zora’s Domain and reclaimed Vah Ruta.
- Went to the Great Hyrule Forest but couldn’t take the Master Sword.
- Found the Ancient Tech Lab in Akkala.
- Criss-crossed Hyrule Field and got blown up by Guardians.
- Climbed Mount Lanayru and OH CRAP THERE’S A DRAGON!
- Cross-dressed my way through the Gerudo Desert and reclaimed Vah Nabooris.
- Froze my butt off in the Gerudo Highlands.
- Rode through Lake Hylia and Faron.
- Took wings in Tabantha and reclaimed Vah Medoh.
- Set my butt on fire on Death Mountain and reclaimed Vah Rudania.
- Decided to freeze my butt off again, but this time in Hebra.
- Stormed Hyrule Castle, kicking butt and taking names.
For combat, I really preferred nimble melee combat. I favored single-handed weapons and spears. I got pretty good with arrows, too, and I would often try to sneak around as an archer before wailing on enemies with a sword.

Guardians – ruining Link’s day, every day.
I did not purchase the DLC, and I probably won’t anytime soon. Why? I simply don’t have time. I didn’t feel like the game was lacking without the DLC, though it looks like it adds some cool content.
What I Loved
The open world was breathtaking. The scenery was truly beautiful, and the whole game was completely explorable. Except for the very edges of the map, there were no invisible walls: if it was there, you could climb it or jump it.

It’s just wild.
As the player, you chose the order of events. In other Zelda games, as in most adventure games, the main quest is completely linear. The player must complete events in a certain order to progress. However, in BOTW, after fully restoring the Sheikah Slate, you can make up your own adventure. The divine beasts are recommended but not required. You can even attempt to fight Ganon immediately after stepping off the Great Plateau (though the King’s ghost rightfully says that would be foolish). If I were to play it again, I’d probably do this order: Necluda/Faron, Great Hyrule Forest, Zora’s Domain, Death Mountain, Tabantha, and Gerudo Desert.
The non-linear unfolding of memories made the story so much more engaging. Until you beat the main quest, you really don’t know everything that happened in the past. You find out bits and pieces about Link, Zelda, and the Champions all throughout the quest. The flashbacks become wonderful rewards for progression.
The Sheikah. My favorite race in BOTW are the Sheikah. They are bona fide ninjas with Jōmon stylistics. They’re the underdog good guys who help Link. They made the greatest technology in Hyrule. And for once, the Sheikah are a living, thriving people group. I loved running around Hyrule wearing the Sheikah armor in honor of the Sheikah.

I want a man bun like that.
The Gorons are hilarious. If the Sheikah are my #1, then the Gorons are my #2. They’re very friendly people with priceless facial expressions.
The music was elegantly serene. It always perfectly complemented the location. From the piano taps while crossing the fields on horseback, to the rambunctious trombones of Goron City, to the violins of Hateno Village that could move you to tears, the music was on point.
Sheikah technology is so cool. Link is running around Hyrule with a mobile phone. The only thing it can’t do is make phone calls!

So, somehow, Hyrule regressed after 10,000 years?
Cooking. I love cooking. The fact that it’s in a Zelda game is incredible. ‘Nuff said.

Iron Chef Link!
Favorite Moments
Meeting the Sheikah monk at the end of every shrine. I loved how each monk had a unique name and pose. I also loved how the blue light would shatter as the monk blessed you with the Spirit Orb.

Every time was a special encounter.
The first horse. Taming, riding, and domesticating my first horse blew my mind. (Remember, I had no spoilers, not even horses.) I still have my first horse, a brown one with a white butt who I named Buttercup.

Look at mah horse – mah horse is amazing!
The first Lynel defeat. I felt UNSTOPPABLE.

This is not easy.
The first blood moon. I panicked because I had no idea what was happening.
Discovering the Great Skeleton in Hebra. It’s in a secret, beautiful cavern under a mountain peak.
Defeating Master Kohga. I delighted in sending him straight down to hell where he belonged. I had zero tolerance for the Yiga Clan.
Finding Gorons in Gerudo Town. They don’t even know how they got it!

It must be the gems.
Building Tarrey Town. Tarrey town is the place where all the races come together to build a productive new settlement together in peace. Everyone gets along. You can find some of the best goods in Hyrule there. It’s also the antithesis of the Great Calamity’s destruction: rather than finding previous towns decimated into ruins, Tarrey Town is the face of the new Hyrule rising from the ashes.
Finding the Hylian Shield. From the beginning, I hoped that the Hylian shield would be available somewhere in the game. I didn’t find it until the end of the game, but when I did, the shield was righteous.
Zelda’s face at the end of the game. #worthit

How is she 117 years old?
Finding out the location of Paya’s birthmark. Paya is probably my favorite character in the game. She’s a sweet, innocent Sheikah lass with a monster crush on Link. She will tell you she got her name from a papaya-seed-shaped birthmark somewhere on her body, but she won’t say where. I spent the whole game wondering where that birthmark was. Forget defeating Ganon and saving the princess, I just wanted to know. After finally completing the heirloom shrine in Kakariko Village (which was my last shrine because I overlooked the diary), Impa finally tells you.
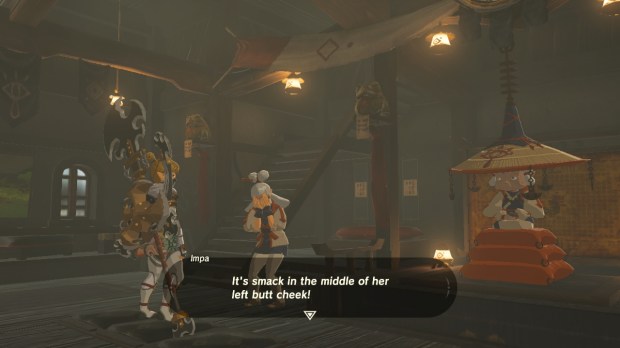
And now we know.
Some Critique
Although BOTW is marvelous, there were a few things I felt could have been improved. These critiques do not in any way mean that the game was poor.
It rains too much in Hyrule. Wanna go climbing? Nope – it’s a slip ‘n slide. Need to cook some food on-the-go? Sorry – flame goes out. Stuck waiting for time to pass? No sitting by a fire. Trying to explode a powder keg on some Bokoblins? Not today. And let’s just hurl some lighting bolts at you while you cross an open field, too. The rain does nothing but block your progress. My biggest frustration was climbing: I couldn’t explore the areas I wanted to go, and I couldn’t pass the time with a fire. Coming back later would be a hassle because I had already climbed high to get there, so I was effectively stuck. It would have been nice to have some sort of item to climb in the rain.
The weapons break too easily. The game mechanic of weapons breaking is pretty clever because it forces the player to always try new weapons. However, it feels like they break too soon. Weapon durability is a significant problem early in the game, because the player has very few inventory slots and strong weapons are hard to find. Later in the game, this is less of an issue. I think some better balancing could have been done.
There was no fishing rod. For being such an outdoorsy game, I was truly surprised that there were no fishing rods in BOTW. Link hunts deer with bows and arrows, but he needs to use bombs to catch fish? This struck me as strange and, to a small extent, thwarted the immersive feeling of surviving in the wild. A fishing rod may have been challenging to implement, but I think it could have been possible as a key item like the glider.
I craved more story points. Much of my gameplay narrative shifted between Divine Beast sagas and open exploration. At times, I felt like there was too much to explore without enough reward. I found myself avoiding enemy hideouts late in the game because I simply didn’t need their weapons or spoils. Having more memories to discover would have been awesome, though I suppose that’s what the DLC is for.
Behind the Scenes
Nintendo released a 4-part video series entitled The Making of The Legend of Zelda: Breath of the Wild that’s really cool. Video links are below.
Final Impression
I love The Legend of Zelda: Breath of the Wild. I can’t wait to see where Nintendo takes the franchise from here!




